DAMA International rozpoczęła oficjalne przygotowania do publikacji trzeciej edycji Data Management Body of Knowledge (DMBoK v3) – kluczowego dokumentu referencyjnego dla wszystkich profesjonalistów zajmujących się danymi.
Nowa wersja DMBoK uwzględnia zmiany, jakie zaszły w ostatnich latach w świecie danych: rozwój AI, eksplozję danych nieustrukturyzowanych, nowe podejścia do Data Governance, wzrost znaczenia architektury danych, a także zmiany regulacyjne, takie jak RODO, CCPA i AI Act.
📌 Co wiadomo na dziś?
🔹 DAMA International powołała zespół redakcyjny i ekspertów branżowych z całego świata, którzy przygotowują zakres i strukturę nowej publikacji.
🔹 Ogłoszono zaproszenie do współpracy – każdy członek społeczności może zgłosić się jako autor, recenzent lub konsultant.
🔹 DMBoK v3 będzie bardziej praktyczny, zorientowany na role i realne wyzwania wdrożeniowe.
🔹 Planowana publikacja to rok 2 kwartał 2027 roku.
📣 Masz doświadczenie w zarządzaniu danymi? Chcesz mieć wpływ na kierunek rozwoju wiedzy w tej dziedzinie?
Zgłoś się do udziału w pracach nad DMBoK v3 przez stronę www.damadmbok.org. Na tej stronie znajdziesz także aktualne informacje na temat tego projektu.
DAMA Poland Chapter aktywnie wspiera działania DAMA International. Zachęcamy polskich specjalistów do zaangażowania się w prace nad DMBoK v3 i współtworzenia przyszłości zarządzania danymi.
3 lipca 2025 r. miała miejsce premiera nowej publikacji pt. „Dane miejskie w praktyce. Podręcznik dla samorządów”, stworzonej z myślą o wsparciu jednostek samorządu terytorialnego w skutecznym zarządzaniu danymi. Podręcznik został opracowany przez zespół ekspertów zrzeszonych wokół Integratora Danych Miejskich IRMiR, przy aktywnym udziale specjalistów z DAMA Poland Chapter.
Cel publikacji
Publikacja stanowi praktyczny przewodnik dla przedstawicieli miast i gmin, pokazujący, jak efektywnie wykorzystywać dane w codziennym zarządzaniu – od podejmowania decyzji strategicznych, przez planowanie przestrzenne, aż po obsługę mieszkańców. Autorzy opisują zarówno wyzwania, jak i gotowe rozwiązania – zgodne z najlepszymi międzynarodowymi standardami.
Dla kogo?
Podręcznik adresowany jest do szerokiego grona odbiorców:
burmistrzów i prezydentów miast,
specjalistów ds. transformacji cyfrowej i smart city,
pracowników urzędów odpowiedzialnych za ewidencję, rejestry i analitykę danych,
a także wszystkich osób zaangażowanych w rozwój polityki miejskiej opartej na danych.
Zakres tematyczny
Wśród poruszanych zagadnień znajdują się m.in.:
cyfrowa transformacja miast,
ocena dojrzałości organizacji w zakresie zarządzania danymi,
pozyskiwanie, udostępnianie i jakość danych,
aspekty prawne (w tym RODO),
wzory dokumentów przetargowych i przykłady postępowań,
analiza ryzyk i rekomendacje do dalszych działań.
Wydarzenie
Premiera podręcznika odbyła się w formule online. Podczas wydarzenia autorzy zaprezentowali kluczowe wnioski, przykłady wdrożeń oraz odpowiedzieli na pytania uczestników. Spotkanie przyciągnęło szerokie grono przedstawicieli samorządów oraz osób zainteresowanych wykorzystaniem danych w sektorze publicznym.
Dostępność
Publikacja jest dostępna bezpłatnie na stronie Obserwatorium Polityki Miejskiej i Regionalnej:
W prace nad publikacją zaangażowani byli eksperci DAMA Poland Chapter. Współtwórcy podręcznika to aktywni członkowie DAMA, którzy wnieśli swoją wiedzę merytoryczną i doświadczenie projektowe: Wiktoria Gromowa-Cieślik, Staszek Radomski, Filip Dzięcioł, Karol Berłowski, Wojciech Łachowski i Arkadiusz Dąbkowski
W tym odcinku podcastu “Big Data, Big Challenges and Big Real Success” Adela Muresan, ekspertka w dziedzinie danych i sztucznej inteligencji z doświadczeniem w sektorze bankowym i doradczym, opowiada o tym, co naprawdę działa w AI – i co nadal pozostaje jedynie mitem.
Tematy, które porusza:
gdzie kończy się hype, a zaczynają rzeczywiste transformacje
jak AI zmienia biznes: nie tylko automatyzacja, ale też personalizacja i działanie w czasie rzeczywistym
dlaczego jakość danych i data governance to klucz do sukcesu
jak wygląda droga od prototypu do skalowalnych wdrożeń
jak budować strategię, komunikację i kulturę danych wokół projektów AI
Adela dzieli się przemyśleniami z perspektywy liderki, która rozwijała inicjatywy AI w różnych środowiskach, pokazując, że skuteczne wykorzystanie danych to nie tylko technologia – to również ludzie, procesy i ciągła nauka.
🎧 Odsłuchaj odcinek tutaj
YouTube
Spotify
🔧 Podcast stworzony przez Sofixit 🔧
Sofixit to firma technologiczna specjalizująca się w tworzeniu innowacyjnych rozwiązań w obszarze danych i sztucznej inteligencji. 🌐 Sprawdź więcej: www.sofixit.pl
Jak co roku, spotkaliśmy się 5 czerwca w Warszawie, w hotelu Renaissance Warsaw Airport, na dorocznej konferencji CDO Forum zorganizowanej przez Evention oraz DAMA Poland Chapter przy wsparciu licznych firm – dostawców rozwiązań z obszaru szeroko rozumianej „data” będących sponsorami wydarzenia. W poprzedzającym dniu odbył się warsztat pt. „Praktyczne vademecum jakości danych” prowadzony przez eksperta od jakości danych Piotra Czarnasa. A kolejnego dnia odbyły się 3 warsztaty online. Poniższa relacja dotyczy głównego dnia konferencji, gdzie spotkaliśmy się na żywo aby wysłuchać prezentacji, dyskutować i nawiązywać kontakty w ramach networkingu. Partnerem generalnym konferencji była w tym roku firma Snowflake, natomiast partnerami strategicznymi firmy IBM i Ab Initio.
Fot. Evention
Prezentacje z sesji plenarnej
Data in orbit
Konferencję otworzył jak zwykle Przemysław Gamdzyk, po czym wystąpił gość specjalny Winfried Adalbert Etzel z Norwegii, członek Data Management Association Norway, z prezentacją „Data in Orbit” („Układ słoneczny” danych), który nawiązując do znanego filmu SF Żołnierze kosmosu” mówił o wyzwaniach w zarządzaniu danymi, cechach, które powinny charakteryzować managerów, i nie tylko, zajmujących się zarządzaniem danymi, np. wspierać inicjatywy i działania w tym obszarze zamiast je wymuszać. Oczywiście znalazła się też chwila na omówienie aspektów jak AI wpływ na DM.
Fot. Sławomir Tomczak
Wdrożenie AI w organizacji: od przygotowania danych do działającej aplikacji
Następnie scenę zajął Piotr Pietrzkiewicz ze Snowflake, który przedstawił doświadczenia firmy w budowaniu rozwiązań AI dla Siemens Energy. W swojej pracy wykorzystują porady i najlepsze praktyki opisane m.in. w ich dokumencie „The data executive’s guide to effective AI”. Mnie ujęło proste, ale zasadnicze hasło, które Piotr zacytował: „There is no AI strategy without a data strategy”. Niestety w firmach zapomina się nierzadko o tej drugiej części i jak to Piotr pokazał na jednym ze slajdów, wystarczy w nazwie projektu umieścić magiczny skrót AI, żeby dostać na niego fundusze. A AI to nie magiczna kula, którą zapytamy i dostaniemy odpowiedź. To mozolna praca nad zbudowaniem wartościowych rozwiązań – w Siemens Energy zbudowano AI playground (piaskownicę), w której przetestowano ponad 300 pomysłów na rozwiązania AI i mały procent z nich doczekał się wdrożenia. Ważnym przesłaniem z prezentacji było, aby AI traktować jako nowego pracownika, który musi zostać wyszkolony na dobrych i licznych danych, a później jego wydajność musi być monitorowana, aby weryfikować czy rzeczywiście dostarcza zakładanej wartości biznesowej.
Fot. Sławomir Tomczak
Prelegent wspomniał o konieczności zmiany sposobu myślenia z silosowego, po obszarach biznesowych, na myślenie zorientowane na produkt danych zapewniające widok 360° na dane klienta czy usługi oferowane przez firmę. Na koniec padła istotna też kwestia, że nie należy zapominać o komunikacji dotyczącej danych i AI, aby budować świadomość w firmie i zarządzać oczekiwaniami, także na poziomie zarządu. Moim zdaniem była to jedna z najciekawszych i najbardziej wartościowych prezentacji tego dnia.
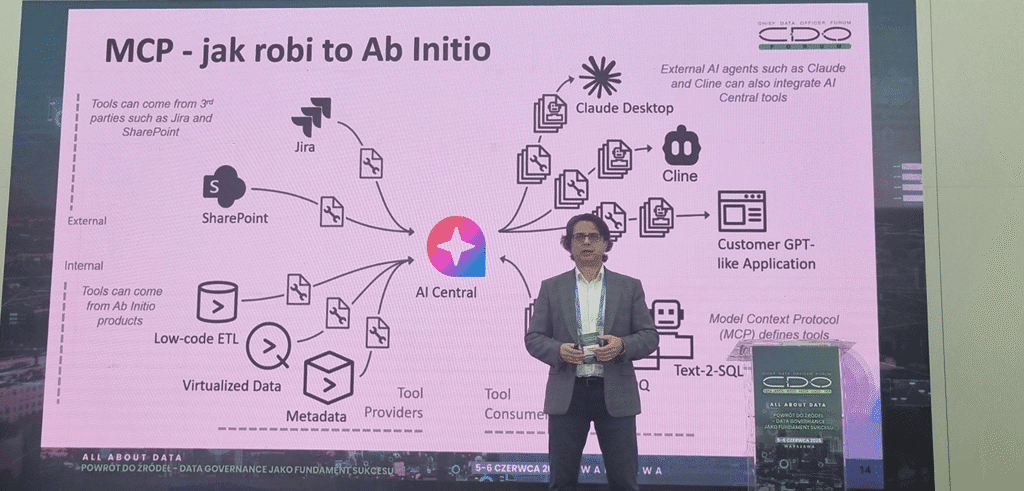
Od generowania tekstu do realizacji zadań: rola kontekstu, pamięci i Model Context Protocol w rozwoju Agentic AI
Następnie Wojciech Małek z Ab Initio zaprezentował bardziej technologiczną prezentację, w której omówił architekturę rozwiązań agentowych, kwestie różnego rodzaju pamięci w rozwiązaniach LLM i RAG oraz halucynacji modeli. Prelegent przedstawił bliżej cechy protokołu MCP, m.in. jego rozszerzalność umożliwiającą dodawanie nowych funkcji jedynie przez uruchomienie i zarejestrowania nowego serwera, bez modyfikacji kodu agenta. Omówił też kwestie użycia MCP przez agentów AI i sposób wykorzystania MCP w budowie rozwiązań agentowych przez Ab Initio.
Fot. Sławomir Tomczak
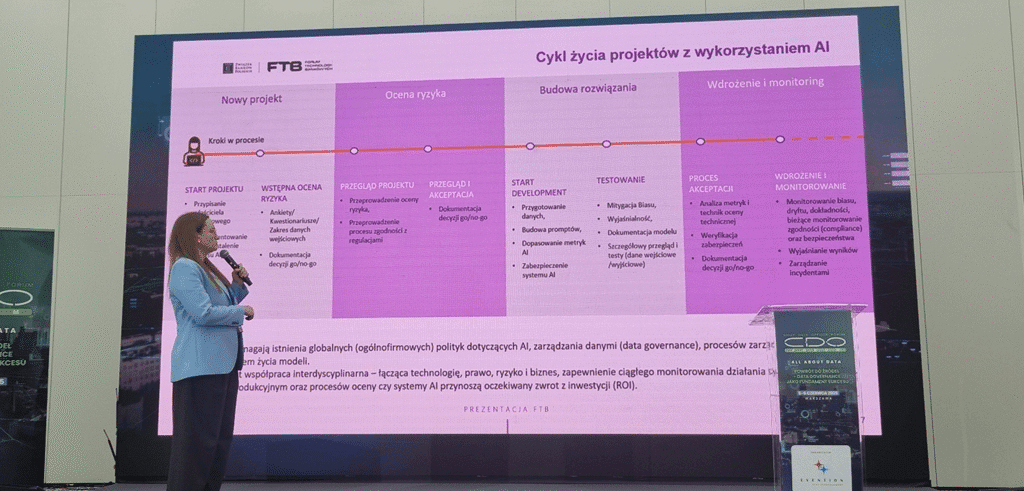
Od danych do chaosu – czyli dlaczego AI Governance potrzebuje CDO
W kolejnym wystąpieniu Aleksandra Kaszuba z IBM zaprezentowała narzędzie Watsonx.governance do oceny i zarządzania ryzykiem dla rozwiązań AI, w tym także zgodności z regulacjami, np. AI Act. Dla ilustracji problemu ze stronniczością AI wynikającą z użytych danych do trenowania modelu zaprezentowała przykład, w którym AI zapytano o wizerunek szefa amerykańskiego i polskiego banku. W Polsce był to mężczyzna w średnim wieku, natomiast w USA była to młoda kobieta. Prelegentka omówiła różnego typu ryzyka występujące przy wdrażaniu rozwiązań AI, zebrane przez IBM w katalogu ryzyk (darmowym) dostępnym na stronach firmy. Zaprezentowała też cykl życia projektu z wykorzystaniem AI i na przykładzie asystenta HR zbudowanego dla unijnej organizacji AMLA i przedstawiła jak używać narzędzi Watsonx.governance do zarządzania wdrożeniami rozwiązań AI. Przedstawiła też zestaw procesów, polityk i narzędzi tworzący framework AI governance przygotowany przez grupę roboczą ds. AI – członków społeczności Forum Technologii Bankowych.
Fot. Sławomir Tomczak
Panel dyskusyjny
W panelu dyskusyjnym pt. „Jak pielęgnować i utrzymać talenty w dziale danych – między produktywnością a rozwojem”, prowadzonym przez Marcina Choińskiego (dyrektora ds. zarządzania danymi z TVN Warner Bros Discovery), szefowie działów zarządzania danych z Alior Bank, GUS oraz przedstawiciele dostawców IQVIA oraz Snowflake dyskutowali z Marcinem o tym jak duża jest rotacja pracowników z ich obszaru, co wpływa na zadowolenie pracownika i co motywuje pracowników z obszaru szeroko pojętej data do pracy. Dominika Rogalińska z GUS opowiedziała o ich inicjatywie Akademii Data Science – wewnętrznej grupie osób zajmujących się tematami zarządzania danymi, z której przez ostatnie 2 lata nikt nie odszedł, a pracownicy są zmotywowani rozwijającymi ich kompetencje zadaniami oraz pewnym dodatkiem finansowym.
Fot. Sławomir Tomczak
Prezentacje w sesjach równoległych
Jakość danych referencyjnych – kluczowym czynnikiem korporacyjnego raportowania
W ścieżkach równoległych prezentacji , których były aż trzy udało mi się posłuchać wystąpienia Piotra Romanowskiego z Medicover. Piotr mówił o wdrożeniu rozwiązania dla zarządzania danymi referencyjnymi (w oparciu o aplikację Metastudio), które przy dużej firmie prowadzącej biznes w kilkunastu krajach okazało się niezbędne, aby dobrze zdefiniować pojęcia biznesowe i słowniki używane w ich biznesie. Wdrożenie pozwoliło zadbać im o jednolite i scentralizowane zarządzanie słownikami danych i powiązanie słowników z danymi w katalogu danych. A wyzwaniem było np. zapewnienie zlokalizowanej obsługi użytkowników w aplikacji, nawet lokalnego języka Dogri używanego w Indiach przez ok 2.6 mln osób.
Z chaosu do ładu, czyli jak opracować plan lotu dla data governance
W innym wystąpieniu Michał Kołodziejski z BitPeak oraz Marcin Wojszcz z Polskiej Grupy Lotniczej S.A. przedstawili prezentację, w której mówili o zmianach w podejściu do danych i zarządzania nimi w PGL wynikającej ze strategii na lata 2024-28 oraz projektu strategicznego „LOT napędzany danymi”. Problemy były, jak to zwykle bywa, m. in. z dostępnością danych (30% osób zgłosiło taki problem) i ich właścicielstwem. Wspólnym wysiłkiem PGL i dostawcy udało się opracować plan lotu – roadmapę działań, w ramach której powołano zespół data governance. Po ustaleniu zakresu prac, zdefiniowaniu pojęć, wybrano na pilota projekt w obszarze danych klienta i w drodze warsztatów ustalono zakres danych, powiązane systemy, procesy i aktorów oraz użyteczność i krytyczność danych. Oczywiście pojawiły się trudności (turbulencje), ale udało im się „miękko wylądować” i obecnie mogą np. wyliczyć ilu dokładnie pasażerów skorzystało z lotów – w kwietniu 2025 było to ponad 915 tysięcy. Ciekawa była forma prezentacji, choć przydałoby się trochę więcej szczegółów i wyjaśnienia czasem enigmatycznych haseł.
Fot. Evention
Od metadanych do wartości biznesowej: Jak wybrać i przekształcić katalog danych w aktywo strategiczne organizacji
W ostatnim wystąpieniu przed sesją plenarną udało mi się posłuchać Bartłomieja Graczyka z Polpharma Group, który w ciekawej prezentacji, choć na początku się na to nie zapowiadało,opowiedział o wdrożeniu w 6 miesięcy raportowania ESG w oparciu o katalog danych. W ramach wdrożenia w 2 miesiące zidentyfikowali kluczowe wskaźniki ESG i zmapowali zródła danych z 17 systemów. W kolejne 2 miesiące wdrożyli rozwiązanie Dataedo dla domeny ESG. Bartłomiej przedstawił drogę jaką podążał zespół wdrożeniowy, problemy, z którymi się zmierzyli, głównie w zakresie jakości danych i udokumentowania źródła danych. Autor przedstawił też kluczowe role w organizacji potrzebne do efektywnego wdrożenia katalogu danych oraz czynniki sukcesu wśród których można wymienić dedykowanych opiekunów danych (na min. 30% etatu) oraz wsparcie wielu członków Zarządu.
Wartościowym składnikiem, którym Polpharma mogłaby się szerzej podzielić był 3-warstwowy model oceny dopasowania rozwiązania katalogu danych do organizacji. Widać było, że zespół odpowiedzialny za wybór podszedł do tego sumiennie i zdefiniował wielorakie kryteria oceny rozwiązania, które później zastosowano do oceny kilku popularnych rozwiązań dostępnych na rynku polskim.
Fot. Evention
Swoją drogą, w ramach działań organizacji DAMA Poland Chapter nasi członkowie stworzyli katalog rozwiązań z szeroko pojętego obszaru przetwarzania danych dostępny pod adresem https://katalog.damapoland.org/kategorie-narzedzi.
GenAI: strażnik governance i jakości danych w BEST SA
Ostatnią prezentacją jaką udało mi się zobaczyć była prowadzona przez Natalię Wasielewską z BEST SA z pomocą Mariusza Kujawskiego z Adastra. BEST użył narzędzia dostarczonego przez Adastra oraz wbudowanych w niego mechanizmów AI do szybkiego tworzenia i wdrażania nowych miar jakości danych. AI proponuje zapytania SQL dla miar, dzięki którym specjaliści mogą szybko zbudować pożądane miary. Efektem tego było wdrożenie w 3 miesiące podobnej ilości miar jak przez ostatnie 4 lata (!). BEST przy implementacji miar jakości danych oparł się o metodykę DAMA – DMBOK , która definiuje wymiary kompletności, unikalności, spójności, poprawności, adekwatności i aktualności danych. Narzędzia AI świetnie sprawdziły się im też przy czyszczeniu danych adresowych. Ciekawym punktem podniesionym przez Natalię była potrzeba obserwacji jakości danych z perspektywy procesów biznesowych, a nie tylko domen danych. Jak dla mnie był tojeden z ważniejszych punktów, które wyniosłem z tej prezentacji. Bo co z tego, że np. jakość i kompletność atrybutu nr telefonu kontaktowegoklienta będzie na poziomie blisko 100%, jeśli ten atrybut nie jest używany w żadnym procesie biznesowym, a z kolei atrybut adres email klienta wypełniony na poziomie przykładowo 30-40% uniemożliwia skuteczną komunikację tym kanałem.
Fot. Evention
Spotkania roundtables
Stolik 5 –Czy rewolucja AI zaczyna być ofiarą własnego sukcesu? Dane, oczekiwania i realia wdrożeń
W przerwie prezentacji odbyły się dyskusje przy stolikach, tzw. Roundtables, których było osiem i podejmowały tematy od bezpieczeństwa danych i ich prywatności przez rolę Chief Data Officer po marketplace danych i wpływ AI na obszar przetwarzania i zarządzania danymi. Ja wziąłem udział w dyskusji o nośnym temacie danych, oczekiwań i realiów wdrożeń rozwiązań AIprowadzonej przez przedstawicieli Neuca oraz Ab Initio. I tu muszę przyznać, że dyskusja jak co roku trochę mnie rozczarowała. Może wynikało to z liczby osób zainteresowanych tematem (overbooking miejsc przy stoliku na poziomie ponad 50%…), może inne aspekty też zaważyły, ale moim zdaniem trudno było utrzymać dyskusję wokół tytułowych wdrożeń, a też niełatwo było dojść do głosu. Ja przynajmniej oczekiwałem konkretnych przykładów i dyskusji dlaczego coś zadziałało lub nie, gdzie AI się sprawdza, a gdzie lepiej w niego nie wchodzić. Z konkretów dyskusji pamiętam, że przedstawiciel jednego z banków mówił o ich doświadczeniach z wdrożenia narzędzi AI, za pomocą których użytkownicy biznesowi mogą tworzyć raporty za pomocą język naturalnego, który AI „przekłada” na odpowiedni kod zapytań SQL. Jednak problemem był odbiór tego przez użytkowników, którzy niechętnie korzystali z rozwiązania, zapewne przez brak zaufania, preferując jednak kontakt z żywym człowiekiem, który może przygotować dla nich taki raport.
Fot. Evention
Zakończenie konferencji
Późnym popołudniem, po wszystkich wystąpieniach nastąpiło losowanie nagród w konkursie, w którym należało odwiedzić wszystkie stoiska dostawców i pozbierać pieczątki, a przy okazji móc zapoznać się z oferowanymi przez nich rozwiązaniami i nawiązać kontakt z dostawcami. W tym roku płeć żeńska miała wyjątkowe szczęście i wszystkie nagrody zgarnęły Panie.
Cenny był też czas networkingu, także z prelegentami, już po stresie wystąpień publicznych, który ja intensywnie wykorzystywałem na nawiązanie relacji i z dostawcami i z fachowcami w branży.
Podsumowanie
Jak zwykle w tym miejscu, w hotelu Renaissance Warsaw Airport, bo CDO Forum odbywa się tam już od paru lat, catering i organizacja stały na wysokim poziomie – sprawna rejestracja, smaczne przekąski i lunch. Aczkolwiek zawsze można coś poprawić i mnie osobiście brakowało na każdej sali programu wystąpień ze wszystkich trzech sal. A przede wszystkim szkoda , że wystąpienia nie były nagrywane przez organizatorów (choćby tylko audio) i udostępnione na stronach CDO Forum. Dużo było wartościowych treści w tych wystąpieniach, a z uwagi na ich zrównoleglenie, fizycznie nie było możliwości, żeby to wszystko zaabsorbować.
W tegorocznej edycji zarejestrowało się 326 uczestników (w poprzednim roku było niespełna 290) reprezentujących szerokie spektrum branżowe, przy czym największą reprezentację miały bankowość i finanse (25%), a łącznie z ubezpieczeniami było to (28%) oraz usługi IT (28%). Ze strony dostawców było to 16 firm, z których duża część uczestniczyła też w zeszłorocznej konferencji. W warsztatach online kolejnego dnia wzięło udział prawie 100 uczestników. Wśród prelegentów szczególnie widać było przedstawicieli branży finansowej oraz medycznej. Natomiast zastanawiające był nikły udział telekomów i mediów, poza TVN, którego CDO uczestniczył w panelu dyskusyjnym i przedstawicielką T-Mobile, która współprowadziła jedną z dyskusji w sesji roundtables.
Podsumowując, to był cenny czas i udział w konferencji uważam za dobrze zainwestowane pieniądze. Bywam na konferencji od paru lat i mam już ją w planach na przyszły rok.
W kolejnym odcinku serii podcastów rozmawiamy z Pawłem Zielińskim, Head of Data & Analytics w Dunapack Packaging – Prinzhorn Group, o tym, jak przekształcić dane w realne decyzje biznesowe.
Poruszane tematy:
czym jest prawdziwa transformacja cyfrowa
jak budować i rozwijać kulturę opartą na danych
jak liderzy mogą wspierać sukces analityki i AI
jak unikać najczęstszych błędów
dlaczego nauka i adaptacja to fundament długoterminowego sukcesu
To rozmowa pełna praktycznych wskazówek, doświadczeń z wdrożeń i strategicznych wniosków dla liderów, którzy chcą realnie zmieniać swoje organizacje dzięki danym.
🔧 Podcast stworzony przez Sofixit
Sofixit to firma technologiczna specjalizująca się w tworzeniu innowacyjnych rozwiązań w obszarze danych i sztucznej inteligencji. 🌐 Sprawdź więcej: www.sofixit.pl
W pierwszym odcinku nowej serii podcastowej Anna Przybył, ekspertka ds. rozwiązań AI i cyberbezpieczeństwa, rozmawia z Barbarą Sobkowiak, Advanced Analytics Manager w Rossmann Polska, o tym, jak skutecznie wdrażać sztuczną inteligencję w realiach biznesowych – z dala od hype’u i buzzwordów.
W tym odcinku dowiesz się:
jak budować kulturę organizacyjną opartą na danych,
jak efektywnie współpracować pomiędzy biznesem a zespołami data science,
jak przechodzić od proof of concept (POC) do skalowalnych wdrożeń AI,
jak unikać najczęstszych błędów projektowych,
jak identyfikować szybkie i skuteczne zastosowania AI w firmie.
Posłuchaj teraz YouTube
Spotify
Pełen praktycznych wskazówek, rzeczywistych przykładów i… metafor z lamą – ten odcinek to obowiązkowa pozycja dla każdego, kto działa na styku biznesu i technologii.
Sofixit to firma technologiczna tworząca innowacyjne rozwiązania w obszarze danych i sztucznej inteligencji. Więcej na www.sofixit.pl.
W najnowszym odcinku serii „Big Data – Big Challenges – and Real Success” omawiane jest „Zwiększenie efektywności architektury. Jak zoptymalizować pracę, kiedy model raportowania przestaje działać sprawnie – studium przypadku”.
Gościem odcinka jest Michał Włodkowski, Data Scientist w Eurocash Group, który dzieli się praktycznymi spostrzeżeniami na temat optymalizacji modeli raportowania, dostosowywania architektury danych do długofalowych potrzeb organizacji oraz zwiększania jej efektywności przy jednoczesnym obniżeniu kosztów.
Poruszane są największe wyzwania wynikające z dynamicznie zmieniającego się środowiska biznesowego, ryzyko vendor lock-in, a także znaczenie odpowiedniego dokumentowania decyzji architektonicznych. Michał wyjaśnia, dlaczego architektury danych wymagają regularnej optymalizacji, jakie kroki podjąć, aby zwiększyć ich wydajność, oraz jak uniknąć pułapek, które mogą prowadzić do spadku efektywności modeli raportowania.
🎧 Zapraszamy do słuchania! 👉 Spotify
👉 YouTube z napisami po angielsku
Sofixit to firma technologiczna tworząca innowacyjne rozwiązania w obszarze danych i sztucznej inteligencji. Więcej na www.sofixit.pl.
W ostatnim odcinku serii „Big Data – Big Challenges – and Real Success” poruszane są kluczowe zmiany prawne, które wkrótce wpłyną na rozwój sztucznej inteligencji i zarządzanie danymi.
Gościem odcinka jest Przemysław Sotowski, Radca prawny i ekspert w dziedzinie AI, który omawia nadchodzące regulacje AI Act oraz ich wpływ na biznes i sektor publiczny.
W odcinku przedstawione zostają kluczowe zagadnienia: 📌 Jakie wyzwania stoją przed organizacjami w kontekście nowych regulacji? 📌 Czym jest klasyfikacja ryzyka i jaka jest rola dostawców systemów AI? 📌 Jakie praktyczne kroki należy podjąć, aby przygotować się na zmiany? 📌 Czym jest Data Act i jak wpłynie na rynek danych?
To odcinek pełen merytorycznych informacji i praktycznych wskazówek dla firm i instytucji, które chcą z wyprzedzeniem dostosować się do nowych regulacji.
🎧 Posłuchaj już teraz:
👉 Spotify
👉 YouTube z napisami po angielsku
🎧 Dziękujemy, że byliście z nami przez całą serię – zapraszamy do zapoznania się z dodatkowymi materiałami!
Sofixit to firma technologiczna tworząca innowacyjne rozwiązania w obszarze danych i sztucznej inteligencji. Więcej na www.sofixit.pl.
W najnowszym odcinku serii „Big Data – Big Challenges – and Real Success” poruszany jest temat „Wyzwania procesu anonimizacji danych” – kluczowego aspektu ochrony prywatności i zgodności z regulacjami prawnymi.
Gościem odcinka jest Marcin Myrta, specjalista w dziedzinie anonimizacji danych, który wyjaśnia różnice między anonimizacją a pseudonimizacją oraz wskazuje wyzwania związane z ochroną danych osobowych w środowiskach produkcyjnych i testowych.
Omawiane są techniki oraz mechanizmy anonimizacyjne, które pozwalają zachować wartość biznesową danych, jednocześnie spełniając wymogi prawne. W odcinku przedstawione zostają również najczęściej popełniane błędy w procesie anonimizacji oraz wskazówki, jak inteligentnie zarządzać danymi, aby zapewnić ich bezpieczeństwo.
🎧 Zapraszamy do słuchania!
👉 Spotify
👉 YouTube z napisami po angielsku
Sofixit to firma technologiczna tworząca innowacyjne rozwiązania w obszarze danych i sztucznej inteligencji. Więcej na www.sofixit.pl.
W najnowszym odcinku serii „Big Data – Big Challenges – and Real Success” przedstawione zostają wyzwania związane z realizacją projektów Big Data, ich specyfika oraz kluczowe umiejętności potrzebne w tej dziedzinie.
Gościem odcinka jest Paweł Matławski, Product Owner w Sofixit, doświadczony specjalista w obszarze analityki biznesowej i projektowania produktów. W rozmowie dzieli się swoimi doświadczeniami, omawiając największe trudności w projektach Big Data oraz różnice między projektami danych a innymi projektami IT.
Prowadzący przybliżają również kluczowe kompetencje analityków danych, narzędzia i technologie wspierające pracę z Big Data oraz kierunki, w których rozwija się branża. Na koniec Paweł poleca cenne źródła wiedzy dla tych, którzy chcą zgłębiać temat analizy i zarządzania danymi.
🎧 Zapraszamy do słuchania!
👉 Spotify
👉 YouTube z napisami po angielsku
Sofixit to firma technologiczna tworząca innowacyjne rozwiązania w obszarze danych i sztucznej inteligencji. Więcej na www.sofixit.pl.