Wnioski i materiały z webinarium przygotowanego przez: Jarosław Banaś, Karol Berłowski, Andrzej Burzyński, Arkadiusz Dąbkowski, Filip Dzięcioł, Wojciech Łachowski w ramach współpracy DAMA Chapter Poland oraz sieci Analityków danych miejskich prowadzonej przez Instytut Rozwoju Miast i Regionów.
Niewidzialna ręka urzędów JST
Ogromne wolumeny danych wpływające na organizację życia każdego mieszkańca w Polsce są przetwarzane w urzędach Jednostek Samorządu Terytorialnego (JST) czyli w urzędach miast, województw, powiatów, gmin. JST gromadzą i przetwarzają dane nie tylko w zakresie bezpośrednio dotyczącym osób fizycznych np. danych meldunkowych, ale prawie w każdym zakresie dotyczącym naszego otoczenia np. architektury, transportu, edukacji, ochrony środowiska, bezpieczeństwa, wodociągów i wielu innych. Dane te służą podejmowaniu decyzji wpływających na organizację życia lokalnej społeczności np. dotyczące lokalizacji szkoły lub tras autobusów. Wybrane dane są przekazywana do rejestrów rządowych stanowiąc podstawę do decyzji na poziomie całego kraju lub Unii Europejskiej. Wybrane dane są udostępniane publicznie stanowiąc źródło referencyjnych danych dla wielu firm. Przetwarzanie danych w JST jest uregulowane licznymi branżowymi przepisami.
Ile Ładu danych jest w JST?
Według badań Unii Europejskiej w 2024 r. Polska zajęła 2 miejsce w badaniu dojrzałości otwierania danych państw UE, co może świadczyć znakomitym zarządzaniu danymi w polskiej administracji publicznej.
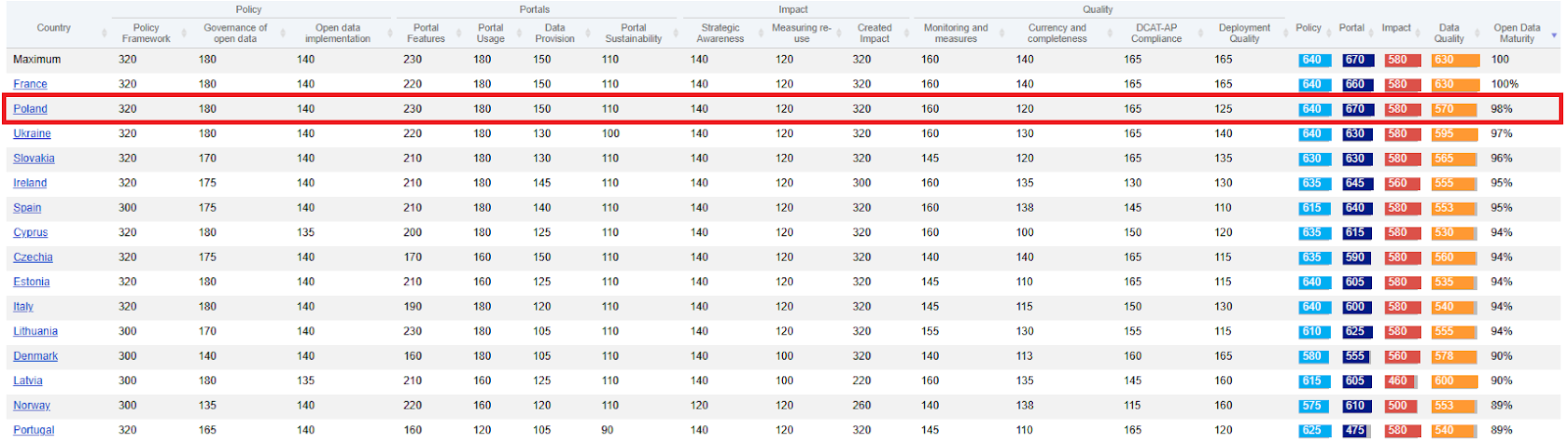
Nieliczne dostępne krajowe badania zarządzania danymi w JST (naukowe oraz kontrole Najwyższej Izby Kontroli) koncentrują się najczęściej na zarządzaniu bezpieczeństwem informacji. Zgodnie z rozporządzeniami w sprawie Krajowych Ram Interoperacyjności od 2012 r. wszystkie JST powinny posiadać wdrożone Systemy Zarządzania Bezpieczeństwem Informacji (SZBI). Mimo tego obowiązku tylko ok 44-75% JST (w zależności od badanej grupy w okresie 2012-2024 r.) wdrożyło SZBI, a przy tym w większości niekompletnie. Wymagania ww. Rozporządzenia dla SZBI są oparte o normę ISO 27001 i są spójne z elementami bezpieczeństwa Ładu Danych opisanymi w Data Management Body of Knowledge (DMBoK). Obszar bezpieczeństwa jest jednym z fundamentów Ładu Danych. Części wspólne wymagań ww. Rozporządzenia oraz Ładu Danych obejmują kluczowe konieczności: określenia ról, przypisania odpowiedzialności, prowadzenia ewidencji (metadanych), określenia zasad dostępu i wielu innych regulacji organizacji pracy z danymi. Powyższe oznacza że badania zarządzanie bezpieczeństwem informacji mogą być wskaźnikiem wdrażania Ładu Danych w urzędach, a ich dostępne wyniki świadczą o znacznych problemach.
O Ładzie danych interaktywnie
Podczas webinarium „Czy Ład Danych w samorządzie jest możliwy?” przedstawiciele DAMA Poland Chapter podjęli dyskusję nad problematyką wdrożenia Ładu Danych w JST. Webinarium zostało zorganizowane 25.04.2025 jako spotkanie w ramach sieci Analityków danych miejskich prowadzonej przez Instytut Rozwoju Miast i Regionów. O potrzebie organizacji spotkania świadczy frekwencja – webinarium zainteresowało 156 przedstawicieli z 70 jednostek samorządowych.

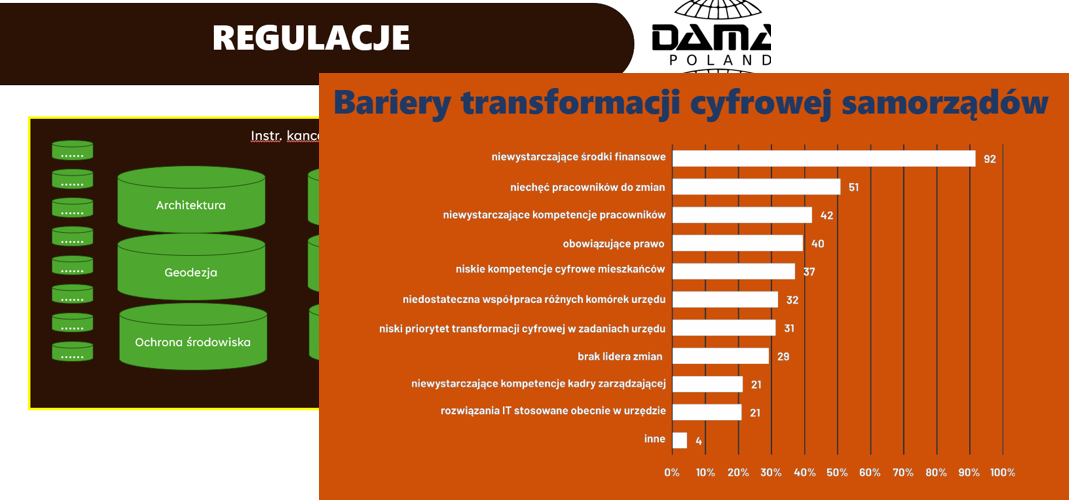
Podczas spotkania Wojciech Łachowski przedstawił korzyści jakie może przynieść Ład Danych w JST, w tym: lepsze decyzje, transparentność, większa efektywność, rozwój usług cyfrowych. Zidentyfikował także główne bariery wprowadzania Ładu Danych w JST analogiczne do generalnych problemów transformacji cyfrowej JST, m.in. brak środków finansowych, opór przed zmianami, problem z zapewnieniem odpowiednich kompetencji, niejasne przepisy, dług technologiczny, zła organizacja pracy. Karol Berłowski rozwinął wybrane problemy. Działalność JST jest wręcz przeregulowana przez liczne, niespójne lub nawet sprzeczne przepisy branżowe. Powyższe jest m.in. przyczyną rozległego problemu ustalenia jednolitej definicji dla jakości danych i operacyjnego właścicielstwa danych. Znaczące nieustrukturyzowanie danych powoduje komplikacje technologiczne zarządzania. JST mają trudność aby pozyskać specjalistów i zaoferować warunki pracy konkurencyjne lub zbliżone wobec sektora prywatnego.
Mimo wielu problemów w niektórych urzędach podejmuje sią zaawansowane działania w celu usprawnienia zarządzania danymi czego przykładem jest Urząd Miasta Krakowa
Fundamenty
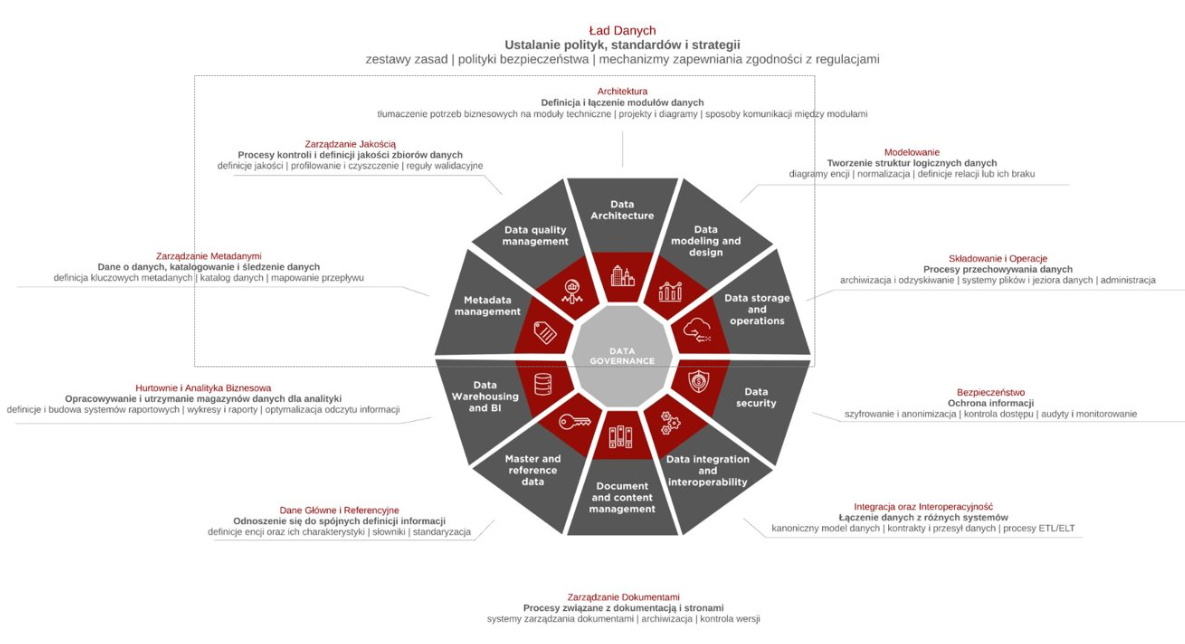
Podczas spotkania Filip Dzięcioł uwzględnił podstawy teoretyczne wskazując na kluczowe aspekty Ładu Danych wg. DMBoK, takie jak strategia, polityka, standardy, nadzór. Omówił podstawowe obszary Ładu Danych: architektura, modelowanie, składowanie i operacje, bezpieczeństwo, integracja i interoperacyjność, zarządzanie zawartością, dane główne i referencyjne, hurtowanie i analityka, metadane, zarządzanie jakością. Zaznaczył problematykę wdrożeniową w organizacji która już przetwarza dane, przedstawił koncepcję wdrożenia piramidy Aikena oraz wskazał rekomendacje implementacyjne.
Sprawdzone rozwiązania
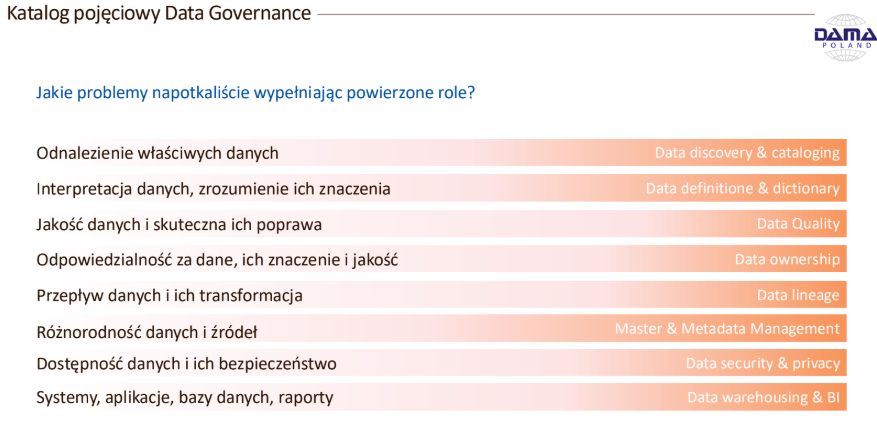
Problemy są podobne w każdym urzędzie. Bazując na swoich doświadczeniach jako eksperta Urzędu Komisji Nadzoru Finansowego, potwierdzonych przykładami z realizacji podobnych projektów w administracji publicznej oraz instytucji finansowych, Andrzej Burzyński przedstawił praktyczne możliwości wdrożenia Ładu Danych. Rozpoczęcie wdrożenia można zacząć od pryncypiów uzgodnionych z kierownikami poszczególnych obszarów merytorycznych. To zapewnia identyfikację rzeczywistych potrzeb i umożliwia określenie ogólnej polityki zarządzania danymi, z której będą wynikały zasady zarządzania danymi. Potrzebne jest uwzględnienie ludzi – ról i odpowiedzialności, potrzeb procesów oraz modelu informacyjnego który usprawni dostęp do potrzebnych danych. Ogólne dokumenty strategiczne są niezbędne do realizacji działań w postaci projektów i usług. Konieczne jest zaangażowanie kadry kierowniczej, w tym najwyższego szczebla, z uwagi na potrzebę wprowadzenia struktury organizacyjnej zarządzania danymi – przypisania odpowiedzialności dla poszczególnych osób za zarządzania danymi, np. w poszczególnych komórkach merytorycznych właścicieli danych. Potrzebne jest powołanie zespołu prowadzącego zagadnienia wdrażania Ładu Danych, skupiającego kompetencje w tym obszarze, stanowiący wsparcie dla pozostałej części jednostki. Zespół wspiera rozwiązywanie szczegółowych problemów np. zarządzania jakością danych. Inne niezbędne działania to m.in. wdrożenie katalogu danych, zidentyfikowanie obszarów tematycznych danych, opracowanie definicji, określenie danych referencyjnych, opracowanie zasad przepływu danych. Wprowadzenie Ładu Danych nie wymaga znaczącego zwiększenia zatrudnienia lub radykalnej zmiany sposobu działania lecz skoordynowania i uspójnienia bieżącej działalności. Wprowadzenie może nastąpić małymi krokami w drodze ewolucji oraz pracy zespołowej całej organizacji. Podmioty przetwarzające dane dla swojej bieżącej działalności mają już pewne elementy organizacyjne które można wykorzystać, zmodyfikować lub rozwinąć w celu osiągnięcia Ładu Danych. Istnieje dużo gotowych metodyk i narzędzi informatycznych wspierających działania.
Wsparcie jest dostępne
Podczas spotkania omówiono potrzeby zarządzania danymi w JST, problemy oraz ich teoretyczne i praktyczne rozwiązania na prawdziwych przykładach. Przykłady rzeczywistego wdrożenia Ładu Danych w polskiej administracji publicznej stanowią dowód że jest to dostępna i już sprawdzona metoda zarządzania także dla podobnych podmiotów – Jednostek Samorządu Terytorialnego. Arkadiusz Dąbkowski wskazał że gotowe wzorce zarządzania danymi można znaleźć w DMBoK, a kompetencje można rozwijać w społeczności DAMA Poland https://damapoland.org/.

Ład danych odpowiedzią bieżące potrzeby JST
Wobec planowanych zmian w przepisach dotyczących bezpieczeństwa informacji w JST (nowelizacji Ustawy o z dnia 5 lipca 2018 r. o krajowym systemie cyberbezpieczeństwa) wprowadzanie zmian zarządzania danymi w obszarze bezpieczeństwa danych staje się dla JST koniecznością. Zmieniając sposób zarządzania danymi w obszarze bezpieczeństwa, JST muszą wprowadzić wewnętrzne regulacje i podjąć działania skutkujące jednoczesnym wprowadzeniem elementów Ładu Danych. Te elementy stanowią znakomity przyczółek do objęcia Ładem Danych także innych obszarów, jak np. dokumenty strategiczne, jakość, zarządzanie danymi podstawowymi i referencyjnymi.

Nagranie z webinarium jest dostępne na youtube:
Źródła przywoływanych badań:
- D. Lisiak-Felicka, M. Szmit, Systemy Zarządzania bezpieczeństwem informacji w administracji samorządowej w Polsce – badanie empiryczne, „Przegląd Organizacji”, TNOiK 2023
- D. Lisiak-Felicka, M. Szmit, Zarządzanie Bezpieczeństwem Informacji w Urzędach administracji samorządowej. Główne problemy, „Współczesny człowiek wobec wyzwań: szans i zagrożeń w cyberprzestrzeni aspekty społeczne-techniczne-prawne”, praca zbiorowa pod redakcją A. Kamińska-Nawrot, J. Grubicka, Uniwersytet Pomorski w Słupsku, Słupsk 2021
- A. Sobczak, Ład danych jako element wdrażania koncepcji otwartego rządu, Roczniki Kolegium Analiz Ekonomicznych nr 46/2017, Kolegium Analiz Ekonomicznych Szkoły Głównej Handlowej w Warszawie,
- https://data.europa.eu/en/publications/open-data-maturity/2024
- https://www.nik.gov.pl/kontrole/P/18/006
- https://www.nik.gov.pl/kontrole/P/24/004