10 grudnia 2025 roku DAMA Poland miała przyjemność uczestniczyć w konferencji Ministerstwa Cyfryzacji dotyczącej wykonanych prac w ciągu ostatnich 2 lat.
Zmieniło się wiele, od rozwoju aplikacji mObywatel o kilkanaście funkcjonalności (w tym e-Punkty Karne, najczęściej odwiedzana zakładka), aż po inicjatywy związane z e-sportem i spójnym reprezentowaniem Polski na konferencjach międzynarodowych przez nowy departament GovTech.
Członkowie DAMA mieli także okazję wziąć udział w konsultacjach Departamentu Zarządzania Danymi, gdzie głównym tematem były ostatnie regulacje, a także zapytanie o nadchodzące zmiany. Każdy mógł zgłosić swoje uwagi, a także posłuchać co na ten temat mają do powiedzienia osoby bezpośrednio odpowiedzialne za bezpieczeństwo informacji w kraju.
Zapraszamy również do streszczenia konferencji opublikowanej na stronie rządowej oraz tych udostępnionych przez naszych członków na LinkedIn:
DAMA Poland stale stara się wspierać Ministerstwo Cyfryzacji, zwłaszcza oddolnie poprzez inicjatywy edukacji (współpraca z IRMiR, współpraca z ALK), czy konsultacji (Miasto Kraków). Jesteśmy dumni ze wszystkich prac wykonanych przez ostatnie lata i gratulujemy świetnych rezultatów.
Tematem „Automatyzacja procesów Master Data Management” wznowilismy cykl spotkań Data 5 o’clock.
Master Data vs Golden Record – czym się różnią?
Na początku omowiliśmy co to jest Master data oraz czym się różni od Golden Record. Golden Record to jedno, wspólne źródło danych dla organizacji, któremu ufamy. Masterdata to dane podstawowe nadające kontekst transakcjom, które odpowiadają na pytania kto, co, gdzie, itp.
Style integracji Master Data
Powiedzieliśmy sobie jakie są cztery wzorce (style) integracji masterdaty: 1) Rejestr a. Dane podstawowe pozostają w systemach źródłowych. b. Tworzy się centralny rejestr z kluczowymi identyfikatorami i minimalnym zestawem atrybutów. 2) Konsolidacja a. Dane z systemów źródłowych są kopiowane i konsolidowane w centralnym repozytorium. b. Służy głównie do raportowania i analizy. 3) Współistnienie a. Dane są zarządzane zarówno w systemach źródłowych, jak i w centralnym hubie. b. Synchronizacja odbywa się w obie strony. 4) Centralizacja a. Dane podstawowe są zarządzane wyłącznie w centralnym hubie MDM. b. Systemy źródłowe pobierają dane z tego hubu.
Automatyzacja w MDM – dlaczego jest ważna?
Po ustaleniu czym jest Master Data Management (MDM) przeszliśmy do omówienia zagadnienia Automatyzacji.
Automatyzacja pozwala na : 1) Oszczędzanie czasu pracy ludzi poprzez wyeliminowanie powtarzalnych i ręcznych czynności 2) Poprawienie jakości danych dzięki automatycznym regułom czyszczenia 3) Przyspieszenie procesów decyzyjnych i minimalizowanie ryzyk 4) Optymalizowanie wykorzystania zasobów i zwiększa efektywość podejmowania decyzji biznesowych
Zaczęliśmy od tego jakie metryki mogą zostać wykorzystane w celu automatyzacji tych procesów: 1) Metoda Levensteina – algorytm służący do mierzenia różnicy między dwoma ciągami znaków 2) Sandex – stosowane do precyzyjnego pozycjonowania i sterowania ruchem 3) BLEU (Bilingual Evaluation Understudy) – Metryka oceny jakości tłumaczeń maszynowych i generowanych tekstów. 4) ROUGE (Recall-Oriented Understudy for Gisting Evaluation) – Metryka oceny jakości streszczeń i generowanych treści. 5) Machine Learning / Gen AI
Obszary zastosowania Automatyzacji w Master data Management to: 1) Reguły czyszczenia danych 2) Przygotowywanie, wytwarzanie i przekształcanie danych 3) Podejmowanie decyzji biznesowych 4) Hierarchie i zasady akceptacji i zatwierdzania 5) Wyznaczenia warunków kiedy proces należy przenieść na AI a kiedy powinien to robić człowiek 6) Ryzyk popełnienia błędu oraz ich eliminowania 7) Pomiary efektywności oraz poziom wpływu na biznes 8) Poznawanie danych i ich analizowanie 9) Dokumentacja procesów oraz tworzenie definicji 10) Inne czynności lub zadania w obrębie etapów,kontrolowania, podejmowania decyzji i ich optymalzacji
Automatyzacja w MDM to nie tylko technologia, ale przede wszystkim strategia poprawy jakości danych i efektywności procesów. W kolejnych spotkaniach będziemy zgłębiać praktyczne przykłady wdrożeń oraz narzędzia wspierające automatyzację.
Z przyjemnością ogłaszamy uruchomienie kolejnej edycji Data 5 O’Clock — wyjątkowego wydarzenia DAMA Poland Chapter, które łączy pasjonatów zarządzania danymi w nieformalnej atmosferze rozmowy i wymiany doświadczeń.
To nie jest prelekcja ani klasyczna prezentacja — spotykamy się przy okrągłym stole, by swobodnie podyskutować, podzielić się praktyką, zainspirować nawzajem, a następnie wyjść na szybką integrację☕🍺
Zachęcamy wszystkich członków DAMA Poland Chapter do wypełnienia ankiety dotyczącej terminu i tematu dyskusji, abyśmy mogli jak najlepiej dopasować spotkanie do Waszych oczekiwań.
📅 Data: 26 listopada 2025 (środa) 📍 Miejsce: Warszawa, biuro firmy PwC, w pobliżu Metra Politechnika 🕔 Godzina: 17:30 – 20:00 (po 20:00 – integracja) 💡Temat: Automatyzacja procesów Master Data Management
Nie przegap okazji do rozmowy o danych w dobrym towarzystwie — do zobaczenia na Data 5 O’Clock!
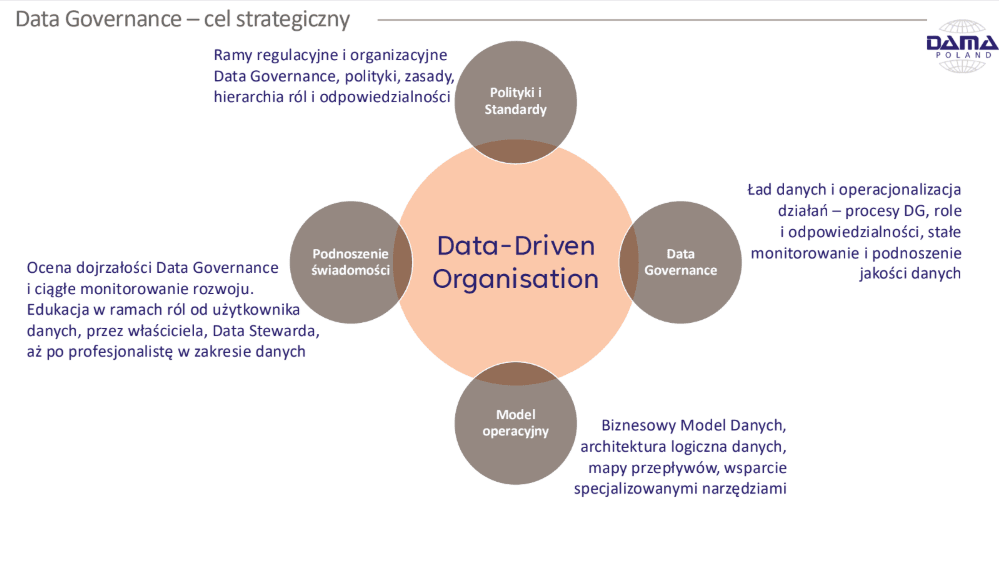
W dzisiejszym świecie strategia danych jest niezbędnym fundamentem organizacji opierających swoją decyzyjność o dane. Wyznacza zasady pracy z informacją oraz plan działania, który umożliwia osiąganie celów organizacyjnych.
Czym jest Strategia Danych?
Zaglądając do DMBoK możemy znaleźć poniższą definicję:
“Strategia to zestaw wyborów i decyzji, które razem wytyczają ogólny, wysokopoziomowy plan działania, aby osiągnąć nadrzędne cele. Powinna ona zawierać biznesowe plany wykorzystania informacji dla uzyskania przewagi konkurencyjnej” DMBoK v2.11
Daje to nam dwie informacje:
Strategia Danych bazuje na, i wspiera Strategię Biznesową Organizacji
Strategia określa wysokopoziomowe dlaczego oraz jak
Definicja ta wspiera przypisanie zarządzania danymi do domeny biznesowej, a nie technicznej. Zapewnia to, że są one ściśle ze sobą powiązane, a dane jako zasób wspierający – będzie wspierał drogę biznesu na rynku.
Motyw ten został dobrze opisany przez DAMA Rocky Mountain Chapter:
“Model dopasowania strategicznego (Strategic Alignment Model) pokazuje miejsce danych w strukturze strategii organizacji – informacja wspiera cele biznesowe (strategia biznesowa), a dane i technologie wspierają operacje (strategia IT). Spójna strategia danych pomaga zintegrować te obszary”1
Strategia, Ład, a Zarządzanie
Warto również odróżnić strategię danych od pokrewnych terminów, takich jak zarządzanie danymi i ład danych. Zarządzanie danymi (Data Management) to zbiór praktycznych działań, koncepcji i procesów służących codziennemu zarządzaniu zasobami informacyjnymi – odpowiada na pytanie „jak zarządzać danymi?”. Ład danych (Data Governance) z kolei to system zasad, polityk, ról i procesów, które zapewniają formalną kontrolę nad zarządzaniem danymi – określa m.in. kto i co robi z danymi, kiedy i gdzie (czyli ramy Kto / Co / Kiedy / Gdziezarządzania danymi)
Z kolei strategia danych nadaje kierunek działaniom związanym z informacją, a także uzasadnia je z punktu widzenia wartości biznesowej związanych z danymi – odpowiada przede wszystkim na pytanie „dlaczego dane są istotne i jak wykorzystamy je dla realizacji strategii biznesowej?”2
Praktyka
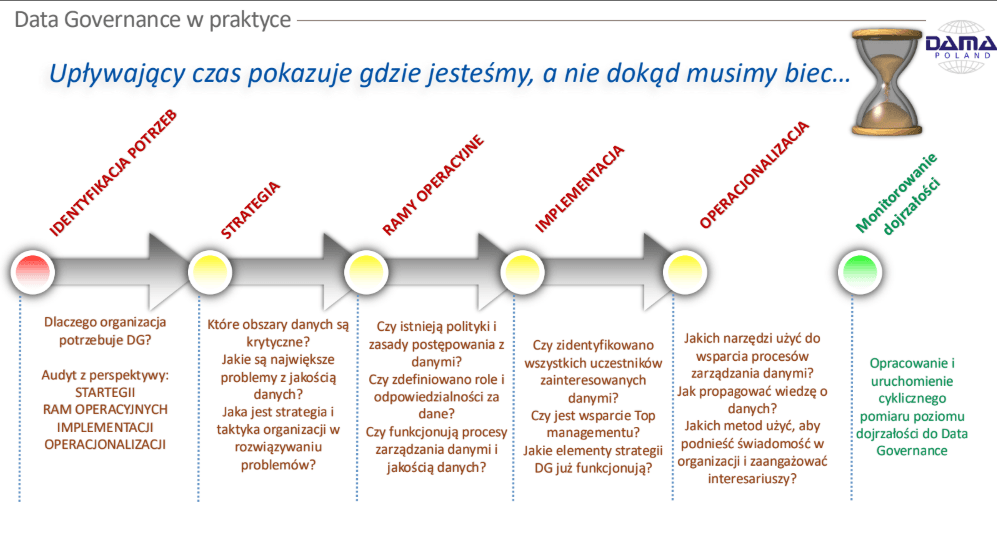
W praktyce oznacza to, że w ramach Strategii należy ustalić jakie są potrzeby dotyczące pozyskiwania, przechowywania oraz przetwarzania informacji, które przedsiębiorstwo ma, bądź może mieć. Pozwoli to na bardziej świadome podejmowanie decyzji, a także zwiększa efektywność zarządzania zasobami informacyjnymi w sposób spójny i dopasowany do aktualnych potrzeb organizacji.
W pierwszym kroku warto określić, kto będzie odpowiedzialny za nadzór nad realizacją strategii. Najczęściej taką rolę pełni Chief Data Officer (CDO) – pełnomocnik ds. danych – który powinien mieć odpowiednie umocowanie w strukturze, dostęp do zasobów oraz zapewnione możliwości decyzyjne w swoim zakresie.
Po ustaleniu głównych ról, oraz zazwyczaj komitetu, bądź biura danych należy zdefiniować nasze “Dlaczego”, które jest zgodne z wizją organizacji, a następnie przejść do celów strategicznych i obszarów, na których należy się skupić – gdzie są największe problemy i możliwości.
Mając te informacje możemy zdefiniować politykę, sposób pracy, a także ogólne role, bądź struktury zespołów, które będą pracowały nad jakością danych.
Na końcu przechodzimy do procesów oraz potencjalnych narzędzi, które mają za zadanie wspierać pożądaną wizję, strategię, oraz przede wszystkim – specjalistów pracujących w danych każdego dnia.
Na co warto zwrócić uwagę
Warto pamiętać, że dane to sport zespołowy. Wszystko nad czym pracujemy jest tworzone przez ludzi i dla ludzi, dlatego też definiując strategię należy myśleć o tym, jaki wpływ będzie ona miała na pracowników. Podobnie działa to w przypadku wybierania narzędzi – czy organizacja posiada niezbędne kompetencje, motywację oraz mechanizmy wspierające rozwój i retencję specjalistów.
Strategia nie jest wykuta w skale – może się z czasem zmieniać wraz z sytuacją w branży, dlatego też iteracyjne podejścia także i tu mają ważną rolę. W tym celu dobrze jest mieć jakieś miary mówiące o tym, czy nasze podejście wciąż działa. Jest to swego rodzaju pętla zwrotna – potrzebujemy informacji, aby móc dobrze zarządzać informacjami, dlatego też odpowiednie metryki, zasoby, czy kompetencje same napędzają rozwój organizacji i pozwalają jej na coraz to dokładniejsze decyzje.
Strategia w sektorze publicznym, a prywatnym
Choć fundamenty strategii danych takie jak wizja, jakość danych czy odpowiedzialność są wspólne dla wszystkich organizacji, podejście do ich wdrażania różni się między sektorem publicznym, a prywatnym. W firmach komercyjnych dane traktowane są jako zasób strategiczny wspierający zysk i przewagę rynkową. Decyzje są szybsze, inwestycje bardziej elastyczne, a technologie wdrażane z myślą o innowacyjności. W sektorze publicznym natomiast priorytetem jest zgodność z regulacjami, przejrzystość, oraz służba obywatelom, gdzie dane publiczne mogą służyć zwiększaniu jakości życia, przejrzystości administracji czy wspieraniu rozwoju usług cyfrowych.
Strategia danych musi tu uwzględniać obowiązki prawne, jak np. otwartość danych czy ochrona prywatności, i często opiera się na szerszym konsensusie politycznym. Mimo tych różnic, dane coraz częściej stają się filarem rozwoju również w administracji – poprawiają jakość usług, wspierają decyzje polityczne i zwiększają efektywność działań urzędów.
Rok 2025 jest przełomowy, ponieważ zaczynamy coraz szerzej i bardziej otwarcie rozmawiać o jakości informacji w Polsce w sferze publicznej. Dzięki temu powstała grupa członków DAMA Poland Chapter współpracująca z Instytutem Rozwoju Miast i Regionów (IRMiR)3 w celu wymiany informacji oraz wsparciu inicjatyw związanych z danymi.
Jednym z efektów tych działań był webinar poświęcony ładowi danych w sektorze publicznym4 oraz publikacja „Dane miejskie w praktyce”5,6, do której lektury serdecznie zachęcamy. Znajdują się w niej praktyczne przykłady wdrażania strategii danych na poziomie lokalnym, z którymi warto się zapoznać.
Odnośniki
Więcej informacji o Data Management Body of Knowledge pod tym adresem
Artykuł “Don’t panic: data management vs data strategy vs data governance” dostępny pod tym adresem
Strona główna Instytutu Rozwoju Miast i Regionów dostępna jest pod tym adresem
Webinar “Czy ład danych w samorządzie jest możliwy?” można obejrzeć pod tym adresem
Książkę “Dane miejskie w praktyce. Podręcznik dla samorządów” można pobrać pod tym adresem
Webinar z publikacji oraz skrótu książki “Dane miejskie w praktyce. Podręcznik dla samorządów” można obejrzeć pod tym adresem
Ostatnim przystankiem każdego CDO Forum są warsztaty, w których uczestnicy mogą zdobyć eksperckiej wiedzy z jednej z prezentowanych dziedzin.
W tym roku już po raz kolejny DAMA Poland miała przyjemność poprowadzić tę część konferencji, tym razem w składzie Wojciech Łachowski (IRMiR), Filip Dzięcioł (Billennium) oraz Arkadiusz Dąbkowski (StepStone).
Warsztaty miały na celu przeprowadzić pewien eksperyment z zakresu Ładu Danych – przeanalizowanie przypadku użycia oraz przygotowanie zestawu polityk, którymi warto się zająć. Przypadek ten tym razem bazował na mieście Olsztyn, w którym postanowiono rozpocząć transformację kulturową czterech warmińskich jezior.
Na wstępie, niezależnie od ćwiczeń praktycznych padło pytanie dotyczące rozlokowania budżetu pomiędzy 10 filarów Ładu Danych zdefiniowanych przez DMBoK. Odpowiedzi mogą być częściowo zaskakujące.
Uczestnicy przede wszystkim postawili na budowanie solidnych podstaw, co jest zgodne z Piramidą Aikena, która, nie uwzględniając samego Ładu Danych stawia właśnie na jakość danych, metadane oraz architekturę.
Następnym punktem była współpraca w kilkuosobowych zespołach w bardzo ograniczonym horyzoncie czasowym – uczestnicy mieli tylko 30 minut na zapoznanie się z dosyć rozbudowanymi założeniami projektu oraz przy pomocy Miro mieli przygotować politykę ładu danych, od której zacznie się ewolucja administracji publicznej w Olsztynie.
Powstały 4 około 8-osobowe zespoły: Team Blue, Team Orange, Team Teal oraz Team Black. Każdy z nich poradził sobie nad wyraz świetnie, skupił się na najważniejszych aspektach i zaproponowali wartościową strategię.
Mimo faktu, że było to piątkowe popołudnie, gdzie grupy miały za zadanie w bardzo krótkim czasie wykonać bardzo trudne zadanie, warsztat ten pokazał, że współpraca specjalistów potrafi zaowocować naprawdę sensownymi wynikami z zakresu zarządzania danymi.
Pierwsza iteracja strategii ładu nigdy nie jest idealna, jednakże daje solidne podstawy, aby na nich stawiać kolejne kroki w dbaniu o jakość informacji przedsiębiorstw.
Zespół prowadzący warsztat z ramienia DAMA Poland:
Ogromne wolumeny danych wpływające na organizację życia każdego mieszkańca w Polsce są przetwarzane w urzędach Jednostek Samorządu Terytorialnego (JST) czyli w urzędach miast, województw, powiatów, gmin. JST gromadzą i przetwarzają dane nie tylko w zakresie bezpośrednio dotyczącym osób fizycznych np. danych meldunkowych, ale prawie w każdym zakresie dotyczącym naszego otoczenia np. architektury, transportu, edukacji, ochrony środowiska, bezpieczeństwa, wodociągów i wielu innych. Dane te służą podejmowaniu decyzji wpływających na organizację życia lokalnej społeczności np. dotyczące lokalizacji szkoły lub tras autobusów. Wybrane dane są przekazywana do rejestrów rządowych stanowiąc podstawę do decyzji na poziomie całego kraju lub Unii Europejskiej. Wybrane dane są udostępniane publicznie stanowiąc źródło referencyjnych danych dla wielu firm. Przetwarzanie danych w JST jest uregulowane licznymi branżowymi przepisami.
Dojrzałość danych Polski w czołówce UE
Według badań Unii Europejskiej w 2024 r. Polska zajęła 2 miejsce w badaniu dojrzałości otwierania danych państw UE, co może świadczyć zaawansowanej organizacji pracy z danymi w polskiej administracji publicznej. Nieliczne dostępne badania zarządzania danymi w JST (naukowe oraz kontrole Najwyższej Izby Kontroli) koncentrują się najczęściej na zarządzaniu bezpieczeństwem informacji. Zgodnie z rozporządzeniami w sprawie Krajowych Ram Interoperacyjności od 2012 r. wszystkie JST powinny posiadać wdrożone Systemy Zarządzania Bezpieczeństwem Informacji (SZBI). Mimo tego obowiązku tylko ok 44-75% JST (w zależności od badanej grupy w okresie 2012-2024 r.) wdrożyło SZBI, a przy tym w większości niekompletnie. Wymagania ww. Rozporządzenia dla SZBI są oparte o normę ISO 27001 i są spójne z elementami bezpieczeństwa Ładu Danych opisanymi w Data Management Body of Knowledge (DMBoK). Obszar bezpieczeństwa jest jednym z fundamentów Ładu Danych. Części wspólne wymagań ww. Rozporządzenia oraz Ładu Danych obejmują kluczowe konieczności: określenia ról, przypisania odpowiedzialności, prowadzenia ewidencji (metadanych), określenia zasad dostępu i wielu innych regulacji organizacji pracy z danymi. Powyższe oznacza że badania zarządzanie bezpieczeństwem informacji mogą być wskaźnikiem wdrażania Ładu Danych w urzędach, a ich dostępne wyniki świadczą o znacznych problemach.
Webinar o danych, który przyciągnął przedstawicieli JST
Podczas webinarium. „Czy Ład Danych w samorządzie jest możliwy?” przedstawiciele DAMA Poland Chapter podjęli dyskusję nad problematyką wdrożenia Ładu Danych w JST. Webinarium zostało zorganizowane jako spotkanie w ramach sieci Analityków danych miejskich prowadzonej przez Instytut Rozwoju Miast i Regionów. O potrzebie organizacji spotkania świadczy frekwencja – w webinarium uczestniczyło 147 przedstawicieli z 46 jednostek samorządowych.
Podczas spotkania Wojciech Łachowski przedstawił korzyści jakie może przynieść Ład Danych w JST, w tym: lepsze decyzje, transparentność, większa efektywność, rozwój usług cyfrowych. Zidentyfikował także główne bariery wprowadzania Ładu Danych w JST analogiczne do generalnych problemów transformacji cyfrowej JST, m.in. brak środków finansowych, opór przed zmianami, problem z zapewnieniem odpowiednich kompetencji, niejasne przepisy, dług technologiczny, zła organizacja pracy. Karol Berłowski rozwinął wybrane problemy. Działalność JST jest wręcz przeregulowana przez liczne, niespójne lub nawet sprzeczne przepisy branżowe. Powyższe jest m.in. przyczyną rozległego problemu ustalenia jednolitej definicji dla jakości danych i operacyjnego właścicielstwa danych. Znaczące nieustrukturyzowanie danych powoduje komplikacje technologiczne zarządzania. JST mają trudność aby pozyskać specjalistów i zaoferować warunki pracy konkurencyjne lub zbliżone wobec sektora prywatnego.
Mimo wielu problemów w niektórych urzędach podejmuje sią działania w celu usprawnienia zarządzania danymi czego przykładem jest Urząd Miasta Krakowa
Podczas spotkania Filip Dzięcioł uwzględnił podstawy teoretyczne wskazując na kluczowe aspekty Ładu Danych wg. DMBoK, takie jak strategia, polityka, standardy, nadzór. Omówił podstawowe obszary Ładu Danych: architektura, modelowanie, składowanie i operacje, bezpieczeństwo, integracja i interoperacyjność, zarządzanie zawartością, dane główne i referencyjne, hurtowanie i analityka, metadane, zarządzanie jakością. Zaznaczył problematykę wdrożeniową w organizacji która już przetwarza dane, przedstawił koncepcję wdrożenia piramidy Aikena oraz wskazał rekomendacje implementacyjne.
Problemy są podobne w każdym urzędzie. Bazując na swoich doświadczeniach jako eksperta Urzędu Komisji Nadzoru Finansowego, potwierdzonych przykładami z realizacji podobnych projektów w administracji publicznej oraz instytucji finansowych, Andrzej Burzyński przedstawił praktyczne możliwości wdrożenia Ładu Danych. Rozpoczęcie wdrożenia można zacząć od pryncypiów uzgodnionych z kierownikami poszczególnych obszarów merytorycznych. To zapewnia identyfikację rzeczywistych potrzeb i umożliwia określenie ogólnej polityki zarządzania danymi, z której będą wynikały zasady zarządzania danymi. Potrzebne jest uwzględnienie ludzi – ról i odpowiedzialności, potrzeb procesów oraz modelu informacyjnego który usprawni dostęp do potrzebnych danych. Ogólne dokumenty strategiczne są niezbędne do realizacji działań w postaci projektów i usług. Konieczne jest zaangażowanie kadry kierowniczej, w tym najwyższego szczebla, z uwagi na potrzebę wprowadzenia struktury organizacyjnej zarządzania danymi – przypisania odpowiedzialności dla poszczególnych osób za zarządzania danymi, np. w poszczególnych komórkach merytorycznych właścicieli danych. Potrzebne jest powołanie zespołu prowadzącego zagadnienia wdrażania Ładu Danych, skupiającego kompetencje w tym obszarze, stanowiący wsparcie dla pozostałej części jednostki. Zespół wspiera rozwiązywanie szczegółowych problemów np. zarządzania jakością danych. Inne niezbędne działania to m.in. wdrożenie katalogu danych, zidentyfikowanie obszarów tematycznych danych, opracowanie definicji, określenie danych referencyjnych, opracowanie zasad przepływu danych. Wprowadzenie Ładu Danych nie wymaga znaczącego zwiększenia zatrudnienia lub radykalnej zmiany sposobu działania lecz skoordynowania i uspójnienia bieżącej działalności. Wprowadzenie może nastąpić małymi krokami w drodze ewolucji oraz pracy zespołowej całej organizacji. Podmioty przetwarzające dane dla swojej bieżącej działalności mają już pewne elementy organizacyjne które można przebudować lub rozwinąć w celu osiągnięcia Ładu Danych. Istnieje dużo gotowych metodyk i narzędzi informatycznych wspierających takie działania.
Podczas spotkania omówiono potrzeby zarządzania danymi w JST, problemy oraz ich teoretyczne i praktyczne rozwiązania na prawdziwych przykładach. Przykłady rzeczywistego wdrożenia Ładu Danych w polskiej administracji publicznej stanowią dowód że jest to dostępna i już sprawdzona metoda zarządzania także dla podobnych podmiotów – Jednostek Samorządu Terytorialnego. Arkadiusz Dąbkowski wskazał że gotowe wzorce zarządzania danymi można znaleźć w DMBoK, a kompetencje można rozwijać w społeczności DAMA Poland https://damapoland.org/.
Wobec planowanych zmian w przepisach dotyczących bezpieczeństwa informacji w JST (nowelizacji Ustawy o z dnia 5 lipca 2018 r. o krajowym systemie cyberbezpieczeństwa) wprowadzanie regulacji zarządzania danymi w obszarze bezpieczeństwa danych JST staje się koniecznością. Zmieniając sposób zarządzania danymi w obszarze bezpieczeństwa, JST muszą wprowadzić regulacje skutkujące automatycznym wprowadzeniem elementów Ładu Danych. Te elementy stanowią znakomity przyczółek do objęcia Ładem Danych także innych obszarów, jak np. dokumenty strategiczne, jakość, zarządzanie danymi podstawowymi i referencyjnymi.
Źródła przywoływanych badań
D. Lisiak-Felicka, M. Szmit, Systemy Zarządzania bezpieczeństwem informacji w administracji samorządowej w Polsce – badanie empiryczne, „Przegląd Organizacji”, TNOiK 2023
D. Lisiak-Felicka, M. Szmit, Zarządzanie Bezpieczeństwem Informacji w Urzędach administracji samorządowej. Główne problemy, „Współczesny człowiek wobec wyzwań: szans i zagrożeń w cyberprzestrzeni aspekty społeczne-techniczne-prawne”, praca zbiorowa pod redakcją A. Kamińska-Nawrot, J. Grubicka, Uniwersytet Pomorski w Słupsku, Słupsk 2021,
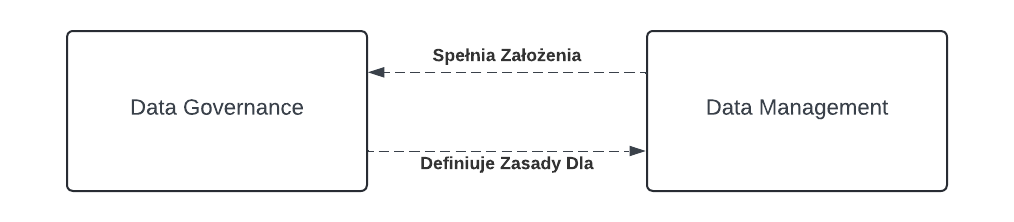
Ład Danych (Data Governance) oraz Zarządzanie Danymi (Data Management) to koncepty mocno ze sobą powiązane, przez co często używane są zamiennie. W języku polskim jest to jeszcze bardziej mylące, ponieważ można o nich mówić jako o Zarządzaniu – co nie jest aż tak drastycznie nieprawdziwe.
Zacznijmy od książkowych definicji z DMBOK.
“Data Governance to sposób sprawowania zwierzchnictwa oraz kontroli (planowania, implementacji, monitoringu, wykonywania) zarządzania zasobów informacyjnych.”
“Data Management to rozwój, wykonywanie, nadzór planów, polityk, programów i praktyk dostarczających, kontrolujących, chroniących oraz zwiększających wartość zasobów informacyjnych w trakcie trwania ich życia.”
Definicje te zatem można zwizualizować następująco:
Jak to wygląda w praktyce
Zespół Ładu Danych jako scentralizowana jednostka spotyka się raz w tygodniu, aby zrobić przegląd aktualnych postępów związanych z Danymi w organizacji. Przegląd zawiera zagregowane metryki dotyczące zespołów oraz produktów informacyjnych, a także wszelkich inicjatyw z nimi związanych. Jeżeli coś wymaga poprawy, zmiany lub restrukturyzacji to ten zespół powinien jasno zdefiniować swoje rekomendacje oraz przekazać je do zespołów Zarządzania Danymi.
Zespoły Zarządzania Danymi jako zdecentralizowana jednostka spotyka się raz dziennie w celu zrozumienia aktualnych priorytetów, projektów oraz potencjalnych zagrożeń, aby odpowiednio pracować ze swoimi zespołami w celu dostarczenia wartości z danych. Ich praca musi być zgodna z wizją zespołu Ładu Danych, od którego otrzymują rekomendacje.
Podsumujmy
Warto zwrócić uwagę na sposób współpracy: scentralizowany zespół ma lepszy ogląd na całokształt, dlatego też są w stanie wystosować trafne rekomendacje (nie nakazy), których wykonanie leży po stronie wielu mniejszych zespołów Zarządzania Danymi, bądź po prostu samych przedstawicieli domen, którzy dzielą pracę pomiędzy swoje mniejsze zespoły.
Proces ten będzie różny w zależności od wielkości organizacji – mniejsze będą miały mniej poziomów, natomiast większe powinny zadbać o to, aby wysokość hierarchii nie zablokowała transferu wiedzy oraz komunikacji wzwyż i wszerz.
Informacje wykorzystywane są od zarania dziejów, przede wszystkim do upewniania się, że nasze decyzje są trafne, co niezaprzeczalnie zwiększa jakość naszych działań.
Z czasem tworzymy coraz to bardziej złożone byty, struktury, czy organizacje. Proces ten w dużej mierze bazuje na danych oraz ich poprawnym wykorzystaniu. Oznacza to, że ich wartość rośnie z czasem – dziś jest to niezwykle cenny zasób mówiący o tym, czy przedsiębiorstwo jest rentowne. Fakt ten staje się także coraz bardziej widoczny i oczywisty.
Praca z samą informacją, jej zdobywanie i składowanie może nie wydawać się aż tak trudnym zadaniem. Problemem jest jednak jej odpowiednie przygotowanie oraz udostępnianie, gdyż każdy człowiek inaczej rozumie świat, ma inny punkt widzenia, doświadczenia oraz cele i preferencje. Często zdarza się, że mówimy o tej samej rzeczy, zgadzamy się ze sobą, a ostatecznie myślimy o czym innym, przez co podejmowane akcje drastycznie się różnią.
Zbudowanie wspólnego języka oraz modelu świata, w którym współpracujemy jest kluczowym aspektem każdego zespołu. Jest to szczególnie istotne przy pracy z danymi oraz w innowacyjnych środowiskach. Pozwoli to na spójne i świadome podejmowanie decyzji, co znacznie zwiększy ich jakość i zredukuje ilość nieporozumień i przestojów z nimi związanych.
Koncepty do zaaplikowania w świecie Danych
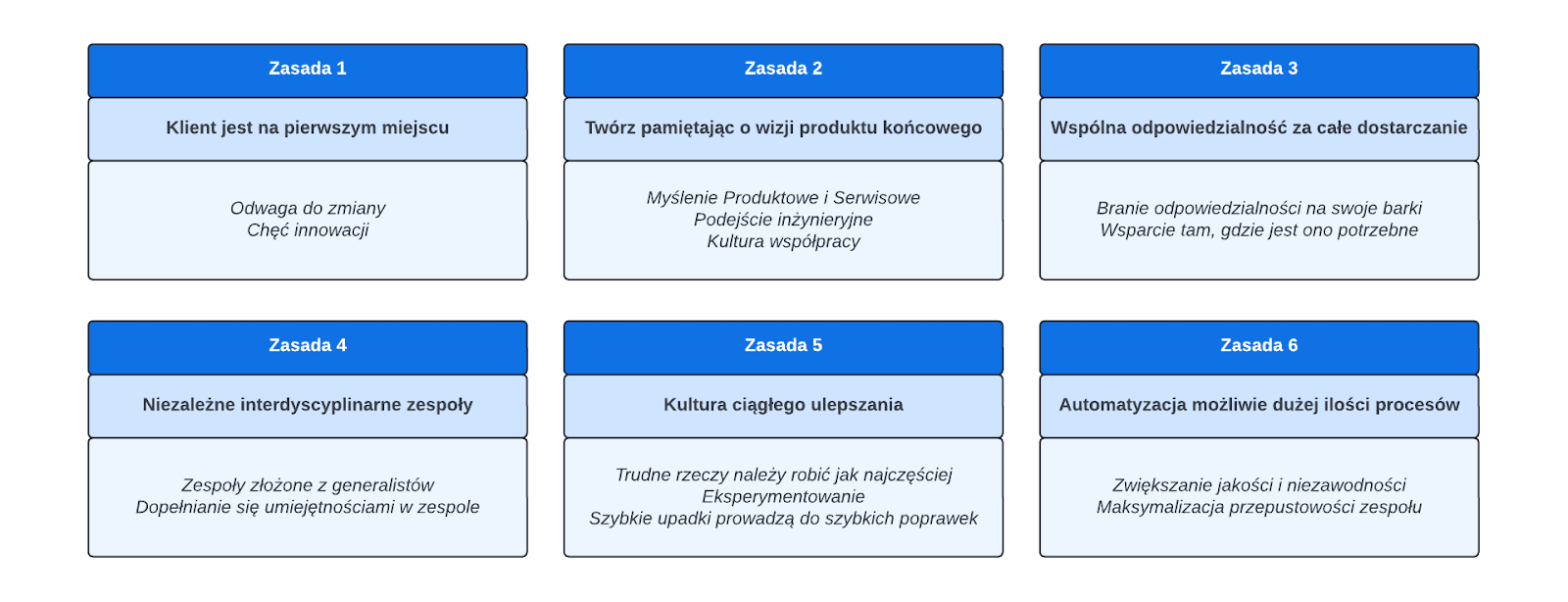
Tworzenie rozwiązań w dużej skali niewątpliwie sprawia, że wszystko jest o wiele trudniejsze, zwłaszcza pod kątem zasad, procesów oraz zarządzania. Mikroserwisy nauczyły nas, że małe i niezależne komponenty komunikujące się ze sobą asynchronicznie poprzez wzorzec X-as-a-Service sprawdza się w dużej skali. Pomysł ten sam w sobie wywodzi się z Filozofii Unixa z 1978 roku1, która mówi o 4 zasadach:
Upewnij się, że program robi tylko jedną rzecz, i robi to dobrze. […]
Oczekuj tego, że wyjście jednego programu staje się wejściem kolejnego, niekoniecznie już znanego. [..]
Buduj systemy i testuj je tak szybko jak to możliwe. […]
Używaj narzędzi prostych w obsłudze, aby wesprzeć innych ich użytkowników. […]
Dla praktyków metodologii DevOps zasady te na pewno są znane – małe iteracje, szybka informacja zwrotna, luźno sprzężona architektura, kultura innowacji.
Zasady DevOps
W 2018 roku wyszła publikacja, która naukowo zbadała i potwierdziła przydatność techniczną i biznesową tych założeń2, dzięki czemu mamy pewność, że tą to koncepty warte wdrożenia.
Ostatecznie powinniśmy być kolejnego konceptu sprzed dekad – Prawa Conway’a. Nie spełnia ono co prawda wymogów bycia pełnoprawnym prawem, choć doczekało się wielu badań potwierdzających jego prawdziwość3. Mówi ono o tym, że komunikacja pomiędzy pracownikami i zespołami znacznie wpływa na architekturę systemów, które zespoły te wytwarzają.
“Każda organizacja, która tworzy systemy (szeroko rozumiane) stworzy system, którego architektura jest kopią struktur komunikacyjnych tej organizacji.”4
Dzięki temu wiemy, że informacja, jak i sposób jej przekazywania znacznie wpływa na jakość oprogramowania. Implikuje to fakt, że kultura jest niezwykle istotna – definiuje jakość organizacji.
Jak widać Prawo Conway’a (1967), Filozofia Unixa (1978) oraz DevOps (2009) dają nam wiele wskazówek dotyczących tego jak efektywnie pracować z, i skalować systemy informacyjne. Skalowanie organizacji może wyglądać bardzo podobnie, zwłaszcza w świecie danych.
Sposoby pracy z Danymi
Dane wnoszą o wiele więcej złożoności, a także potencjalnej wartości, ze względu na fakt, że dodajemy nowe typy systemów i przepływów do naszych architektur. To samo dotyczy AI w ostatnich latach.
Jest to możliwe dzięki odpowiednim metodologiom programistycznym. AI nie może być stabilne i niezawodne, jeśli nie mamy odpowiednich fundamentów danych, które obejmują właściwą kulturę i zarządzanie.
Doświadczenie pokazuje, że świat danych wciąż jest mocno chaotyczny i nieuporządkowany, jednak sytuacja znacznie się poprawia dzięki technologii (m. in. MS Fabric lub Purview, Snowflake, BigQuery lub Redshift) oraz świadomości (m. in. Data Management Body of Knowledge). Jednak nadal brakuje wielu ludzi, kompetencji, budżetu i ustalania odpowiednich priorytetów.
Ostatnie dekady w świecie Danych koncentrowały się na jednym scentralizowanym źródle prawdy, co jest świetnym pomysłem, który pomógł nam osiągnąć dzisiejszy poziom zaawansowania. Jednak w tym przypadku Prawo Conway’a sugeruje, że centralizacja informacji implikuje posiadanie pojedynczego zespołu odpowiedzialnego za nią, co tworzy wąskie gardło zgodnie z zasadami DevOps i zdecydowanie nie jest wspierane jest przez Filozofię Uniksa.
Może to nie być wystarczające, ponieważ nie możemy w nieskończoność skalować pojedynczego zespołu, o czym dobrze mówi Liczba Dunbar’a5. Takie skalowanie zgodnie z Filozofią Unixa oraz DevOps się nie utrzyma. Oprogramowanie poradziło sobie z tym poprzez asynchronizację komunikacji oraz elastyczne skalowanie poprzez Cloud Computing oraz Mikroserwisy.
Jak w takim razie możemy zaaplikować to do naszych zespołów? Rozwiązaniem zdaje się być Data Mesh szerzej opisany w tym artykule.
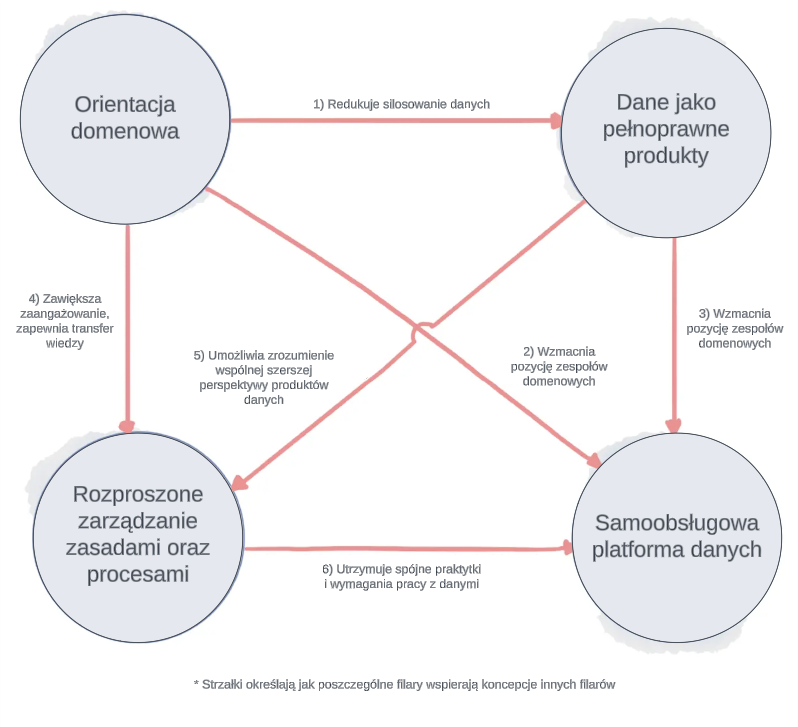
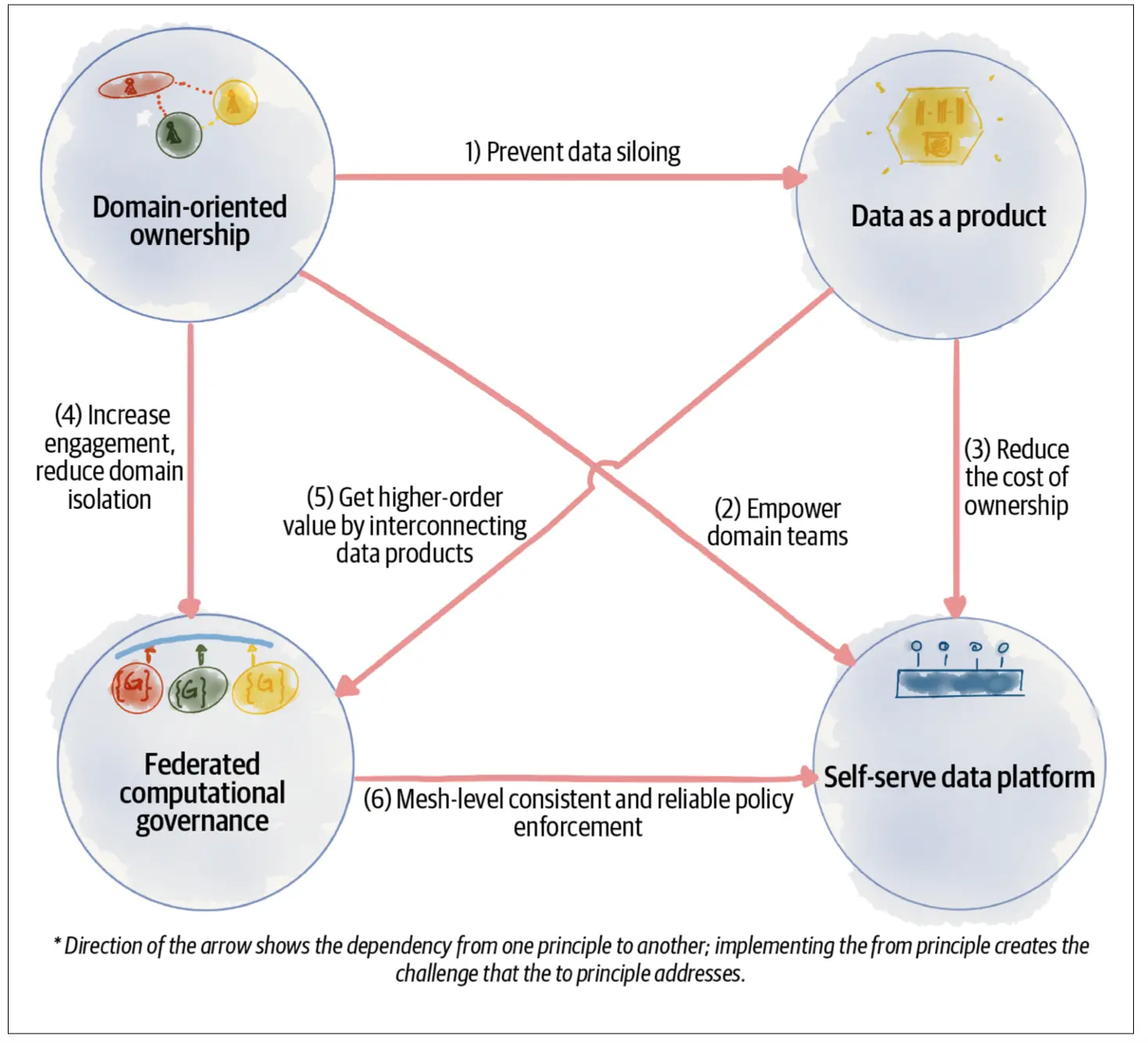
Filary Data Mesh i relacje między nimi
Zamiast tworzyć fizycznie scentralizowany zespół oraz oprogramowanie (Data Warehouses, Data Lakes, Data LakeHouses) możliwe jest utworzenie spójnego i ujednoliconego widoku na fizycznie rozproszone dane, przy pomocy technik wirtualizacji, oraz rozproszyć właścicielstwo poszczególnych zbiorów danych, zapewniając przy tym spójne procesy komunikacji pomiędzy producentami oraz potencjalnymi konsumentami. Usprawni to komunikację, a co za tym idzie – architektury systemów, kulturę oraz zwiększy ilość innowacji. Wynikiem będzie minimalizacja zależności oraz szybkie testowanie zmian, co jest bezpośrednio promowane przez Filozofię Unixa, Prawo Conway’a oraz kulturę DevOps.
Dane jako pełnoprawne Produkty (zapewnianie odpowiedniej jakości oraz budżetów dla Danych, a także dedykowanych od nich specjalistów)
Samoobsługowa Platforma Danych (ujednolicony wgląd, decentralizacja oraz asnychronizacja prac nad informacjami w celu zapewnienia możliwości innowacji, o czym mówi podejście mikroserwisowe)
Rozproszone zarządzanie zasadami i procesami (dzielenie się wiedzą wewnątrz domeny oraz pomiędzy nimi).
Podsumowanie
W ciągu ostatnich dekad przeprowadzono wiele badań mających na celu usprawnienie pracy z oprogramowaniem. Powstało wiele konceptów i metodologii, które mniej lub bardziej się sprawdzały i są dziś wykorzystywane na co dzień. Teraz potrzebujemy upewnić się, że świat Danych nie pozostaje w tyle. Prawo Conway’a jasno wskazuje co powinniśmy zrobić w związku z powyższymi założeniami. Przede wszystkim należy zadbać o kulturę oraz świadomość w tym zakresie tak, abyśmy sami mogli usprawniać naszą codzienną pracę. Założenie to wsparte jest także przez tzw. Turkusowe Organizacje.
Data Mesh wywodzący się z systemów rozproszonych jest bardzo odważnym konceptem, który ma zastosowanie oraz odpowiednie uzasadnienie. Niestety wiele implementacji pokazało jak trudne jest rzeczywiste wdrożenie. Jest to wciąż koncept eksperymentalny i wymaga wielu lat edukacji, pracy, ciągłego budowania kultury, silnego Data Governance, a także dostosowania samego podejścia pod specyfikę organizacji.
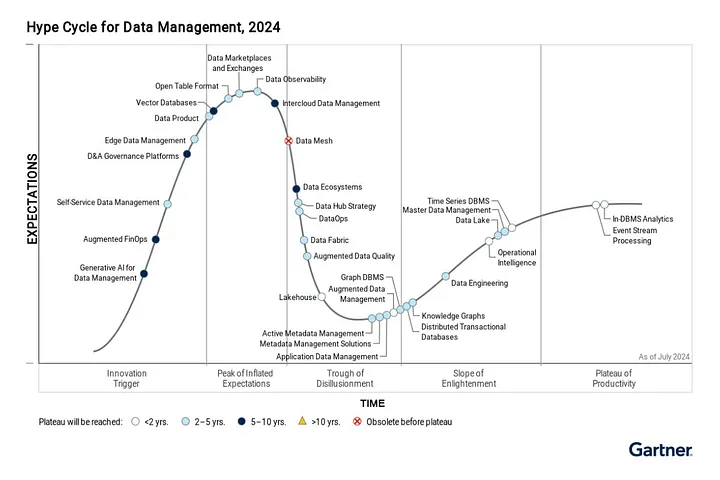
Przebudowa struktur fizycznych oraz komunikacyjnych w dużej organizacji to nietrywialne zajęcie, które pochłania zarówno wiele czasu, jak i budżetu. Świadomość tego, że jest to eksperyment sprawia, że podjęcie tego ryzyka jest bardzo ciężko uzasadnić, a sam sposób wdrożenia musi być bezpośrednio dopasowany pod kulturę i domenę przedsiębiorstwa. Możemy wywnioskować z tego, że podejście Data Mesh wciąż wymaga standaryzacji, dobrych praktyk wielu pomyślnych, jak i niepomyślnych wdrożeń, z których liderzy wyciągną wnioski. Firma Gartner jasno wyraziła swoje stanowisko dotyczące Data Mesh – nieużyteczne przed osiągnięciem dojrzałości, choć dojrzałość nie nastąpi bez wielu prób i dalszych innowacji.
Coroczny Hype Cycle Zarządzania Danymi na rok 2023, Gartner7
Data Mesh to zdecentralizowane podejście do zarządzania danymi w dużej skali opierające się o cztery filary mające za zadanie wytworzenie pewnej kultury i jakości pracy.
Oznacza to, że:
Jest to podejście skierowane nie tylko na technologię, ale przede wszystkim na ludzi.
Jest to podejście pracy zdecentralizowanej, gdzie autonomia jest na dole organizacji.
Jest to podejście stosowane w dużej skali.
Pomysłów na pracę z danymi w organizacji jest wiele, ten jednak proponuje skupienie się na zasobach ludzkich, które, dzięki zaakceptowaniu prawa Conway’a1, mogą być efektywnie wykorzystane bez wiecznej walki z naturą człowieka, jak i przedsiębiorstwa.
Data Mesh rekomenduje iteracyjną ewolucję organizacji w kierunku wyznaczonym przez liderów zarządzania informacją w rozproszonych środowiskach. Transformacja ta opisana została czterema filarami, które są zestawem rekomendacji i próbą utworzenia nowych najlepszych praktyk w świecie danych.
Cztery Filary Data Mesh
Domeny
Organizacje wymagają coraz większej skali oraz dynamiki swojej działalności. Aby to osiągnąć poszczególne departamenty muszą redukować oczekiwanie na inne zespoły oraz decyzje płynące z zewnątrz. Sprawia to, że autonomia jest głównym czynnikiem napędzającym biznes. Okazuje się, że zorientowanie domenowe znacznie wspiera te postulaty.
Podejście domenowe pojawiło się już w 2003 roku w kontekście programistycznym, natomiast w przypadku organizacji, w prostych słowach, oznacza tyle, że należy zapewnić wykonywanie przepływu pracy od początku do końca wewnątrz jednego zespołu (lub grupie zespołów) złożonego ze wszystkich wymaganych na co dzień kompetencji. Pozwala to na dużą autonomię oraz znacząco zmniejsza liczbę nieporozumień, jako że łatwiej się porozumiewać jednym językiem, w jednym kontekście. Jest to również zgodne z Prawem Conway’a2 oraz Liczbą Dunbar’a3. Ostatecznie powinniśmy otrzymać tzw. Agile Release Train4, który jest wirtualną organizacją złożoną z zespołów Agile.
Dane jako Produkt
Od lat podejście projektowe w stylu kaskadowym przekształcane jest w podejście oparte o produkty żyjące zgodnie z metodykami zwinnymi. Dane jednak od zawsze były produktem pobocznym, odkładanym na dysku i czekającym na dalsze procesowanie.
W przypadku Data Mesh chcemy zadbać o jakość, niezawodność oraz transparentność informacji, a do tego potrzebne jest zaaplikowanie podejścia inżynieryjnego do samych danych i tego, co za nimi idzie.
Dziś dane to monetyzowalny produkt o konkretnej wartości, który jest stale udoskonalany przez konkretną domenę oraz posiada całą charakterystykę pełnoprawnego modułu składającego się z kodu, danych oraz wszystkich innych wymaganych artefaktów.
Koncept Data Mesh jest wspierany przez takie pojęcia jak Data Product, Data Ownership czy Data Contract.
Samoobsługowa Scentralizowana Platforma Danych
Dane niosą coraz większą wartość, od prostej analityki i diagnostyki, aż po skomplikowane algorytmy predykcyjne i kognitywne wymagające bardzo wysokiej jakości ogromnych stale przetwarzanych informacji. Organizacja musi mieć zapewnione miejsce, w którym może odnaleźć dane, wstępnie się im przyjrzeć, ustalić z kim o nich rozmawiać oraz na jakich zasadach można z nich korzystać. Z pomocą przychodzi Platforma Danych oraz Katalog Danych.
Platforma Danych pozwala na autonomię osób poszukujących danych. Jest to bardzo duża zmiana kulturowa, ponieważ taka zdolność organizacji zwiększa ilość oraz jakość inicjatyw, promuje przejrzystość prac i zachęca do rozwoju, a nawet zdrowej rywalizacji, w czym pomóc może m.in. Grywalizacja5.
Federacyjne Ustalanie i Zarządzanie Praktykami
Ostatecznym filarem jest zarządzanie praktykami (Governance). Zespół wspierający złożony z najbardziej doświadczonych osób, w tym członków domen, ustala to, w jaki sposób warto pracować oraz jak kontrolować rozwój domen w dobrym kierunku. Jest to ogromne wsparcie, zwłaszcza w wysoce uregulowanych środowiskach, gdzie część zasad zależy od domeny, jednak wiele zależy od całej branży. Spojrzenie z góry nie tylko pomaga znaleźć wąskie gardła oraz problemy, lecz także dobre praktyki, które warto rozdystrybuować w całej organizacji. Wymiana doświadczeń, wspólne spojrzenie na przedsiębiorstwo, oraz aplikowanie coraz to nowszych wymagań i praktyk z zewnątrz to przykłady korzyści wynikające ze współpracy zespołu wspierającego.
Podsumowanie zasad, zależności oraz korzyści płynących z wykorzystania Data Mesh6
Rozpoczęcie Prac
Implementacja tak dużych zmian wymaga przygotowania strategii, planowania oraz nauki na każdym poziomie całego przedsiębiorstwa. Data Mesh stawia przed nami bardzo wymagające założenia, wdrożenie których może się zwyczajnie nie udać, choćby przez sam fakt częstych zmian na stanowiskach decyzyjnych, nie mówiąc o ciągłym rozwoju oraz zmianach kierunku organizacji.
Nie bez powodu Gartner umieścił Data Mesh jako “obsolete before plateau”, które może zostać osiągnięte za kilka lub kilkanaście lat.
Coroczny Hype Cycle Zarządzania Danymi na rok 2023, Gartner7
Bez względu na eksperymentalność tego podejścia wiele organizacji decyduje się na implementację, aby potencjalnie zyskać ogromną przewagę na rynku8.
Rozpoczynając implementację należy zadbać o 4 ważne aspekty:
Wsparcie sponsora C-Level
Ustalenie zespołu odpowiedzialnego za inicjatywę (Data Mesh Council)
Wykonanie warsztatów w celu zrozumienia AS-IS oraz TO-BE
Znalezienie (i/lub wyszkolenie) osób potrafiących i chcących szerzyć dobre praktyki
Wdrażanie Data Mesh nie jest tanie, ani szybkie, dlatego też decyzja ta musi być dobrze uzasadniona i zaplanowana. Bez względu na podejście warto pamiętać, że zasady wymienione w poprzednim rozdziale są uniwersalne i ich implementacja – zarówno pod pełnym szyldem Data Mesh, bądź osobno jako innowacje – dają ogromne korzyści na polu technologicznym oraz kulturowym.